PBCTF 2021 - Not Password (2 solves)
Reversing Reductions
October 11, 2021
rev
sat
sat3
np-complete
Not Password
Description:
Not Password is a program where you, well… type not a password and totally does not check your password for correctness.
Author: theKidOfArcrania
We are given two files:
np: an ELF binarylockfile: a large (~980MB !) blob of unknown data
This challenge ended up being a really cool exploration of NP-complete reductions and how to reverse them. It took me a solid 24 hours to solve this problem (including a 6 hour nap in the middle of that) and I learned (and re-learned) a lot about complexity theory during the process.
If you don’t know what P or NP means or like me, it’s been a while since your formal methods in computer science in college, I’ve included a section with everything you need to know about complexity theory to solve this problem.
Files
- np: original binary
- np.bndb: my binary ninja file
- graph.pdf: a cool graph I generated
- lockfile.bz2: updated lockfile
Complexity Theory 101
Boolean Satisfiablility (SAT)
Assume we have some boolean variables:
a: bool
b: bool
c: bool
and an arbitrarily complex boolean expression using these variables:
x = (a and (not b)) and ((not b) and ((not a) or c))
The Boolean Satisfiability problem asks: are there values for a,b and c such that the whole expression (x) is True?
One solution is to brute force the combinations of input variables:
for a in [False, True]:
for b in [False, True]:
for c in [False, True]:
x = (a and (not b)) and ((not b) and ((not a) or c))
if x:
print(f'Solution: a={a}, b={b}, c={c}')
Solution: a=True, b=False, c=True
But as you can see, this is really inefficient; if we add another variable, we double the number of possible input combinations. In general, the number of solutions we have to check is 2^N where N is the number of variables.
However, if we are given a possible solution, e.g. (True, False, True), we can verify this quickly. Assuming we have to do K*2^N work to solve, we only need to do K work to verify.
Pedantic note: In this construction, verifying a SAT problem is exponentially faster than solving it, but not necessarily polynomial yet because K can still be exponential with respect to N. However most of the time, when we say “SAT” problem, we assume that K is polynomial (i.e. it could be something like 4N^3 + 2N^2 + 10). We will get around this problem later with 3SAT.
Pedantic note pt. 2: There is a distinction between SAT as a decision problem and SAT as a search problem. As a decision problem, the goal is simply to say “yes this expression has a solution” or “no this expression is not solvable” and we don’t actually care about what the solution is. In practice though, we usually do care about the solution and so we convert SAT to a search problem where the answer is a specific positive example. Note that we can use a SAT decision oracle to generate a solution in the following way: if the original expression is unsatisfiable, return unsatsfiable. Otherwise, fix the first variable to false and evaluate. If that is satisfiable, the first variable must be false, otherwise it must be true. Continue doing this with the next variable, etc… This approach takes only linearly more time than the SAT decision problem itself and so most of the complexity theory results still hold for SAT as a search problem.
P vs. NP
We’ve seen that SAT can be verified in polynomial time, but may require exponential time to solve. Now imagine we have the following algorithm:
import random
a = bool(random.randint(0,1))
b = bool(random.randint(0,1))
c = bool(random.randint(0,1))
x = (a and (not b)) and ((not b) and ((not a) or c))
if x:
print(f'Solution: a={a}, b={b}, c={c}')
This algorithm is nondeterministic (because we initialize a, b and c to random values) but runs in polynomial time. This Python representation won’t always give us the solution but it can.
When a problem is solvable by a nondeterministic algorithm in polynomial time, we say that is in the class NP. Problems that are solveable in polynomial time with a deterministic algorithm are in the class P. It is a famous open question whether P=NP. I.e. whether all problems that can be verified in polynomial time can also be solved in polynomial time.
If we imagine each of the random.randint calls splits into two threads with one taking the value False and the other True, then we would end up with 8 threads by the time we get to x = ... and we would be guaranteed to find a solution assuming one exists.
In a nondeterministic algorithm, you can either imagine that the algorithm evaluates all branches in parallel (similar to the threading metaphor above) or it guesses the right value at each branch. It is worth noting that you can’t actually use nondeterministic alrgorithms to solve problems on classical hardware. The best you can do is approximate the solution by sampling a bunch of times (i.e. we could run the python program above repeatedly until we get a solution). However, this is no better than our original brute force search.
It may seem like a pointless classification, but there are some physical systems that can solve NP problems like this in polynomial time. For example, using Shor’s Algorithm, a quantum computer can factor an integer in polynomial time, in some sense by evaluating all the possibilities simultaneously and boosting the probabilities of the correct answer.
I would also like to take this moment to introduce NP-CTF: CTF problems that can be solved in polynomial time with a nondeterministic Turing machine.

SAT Solvers + Abstract Syntax Tree
Now discussing these theoretical concepts is fun and all, but how do we actually create and solve boolean expressions in practice? Well, it turns out that most of the boolean expressions you encounter in practice can be solved pretty fast with magical heuristic searching strategies. Smart people have packaged up this magic into SAT solvers like z3.
For example, we can solve our previous example with the following code:
from z3 import *
# Define our variables.
a = Bool('a')
b = Bool('b')
c = Bool('c')
# Create our symbolic boolean expression.
x = And(And(a, Not(b)), And(Not(b), Or(Not(a), c)))
s = Solver()
s.add(x) # Tell the solver we want x to be True
if s.check() == sat:
print(s.model())
else:
print('no solution')
[b = False, a = True, c = True]
When we run the line
x = And(And(a, Not(b)), And(Not(b), Or(Not(a), c)))
we aren’t actually evaluting anything; rather we are creating an abstract syntax tree representing this expression:
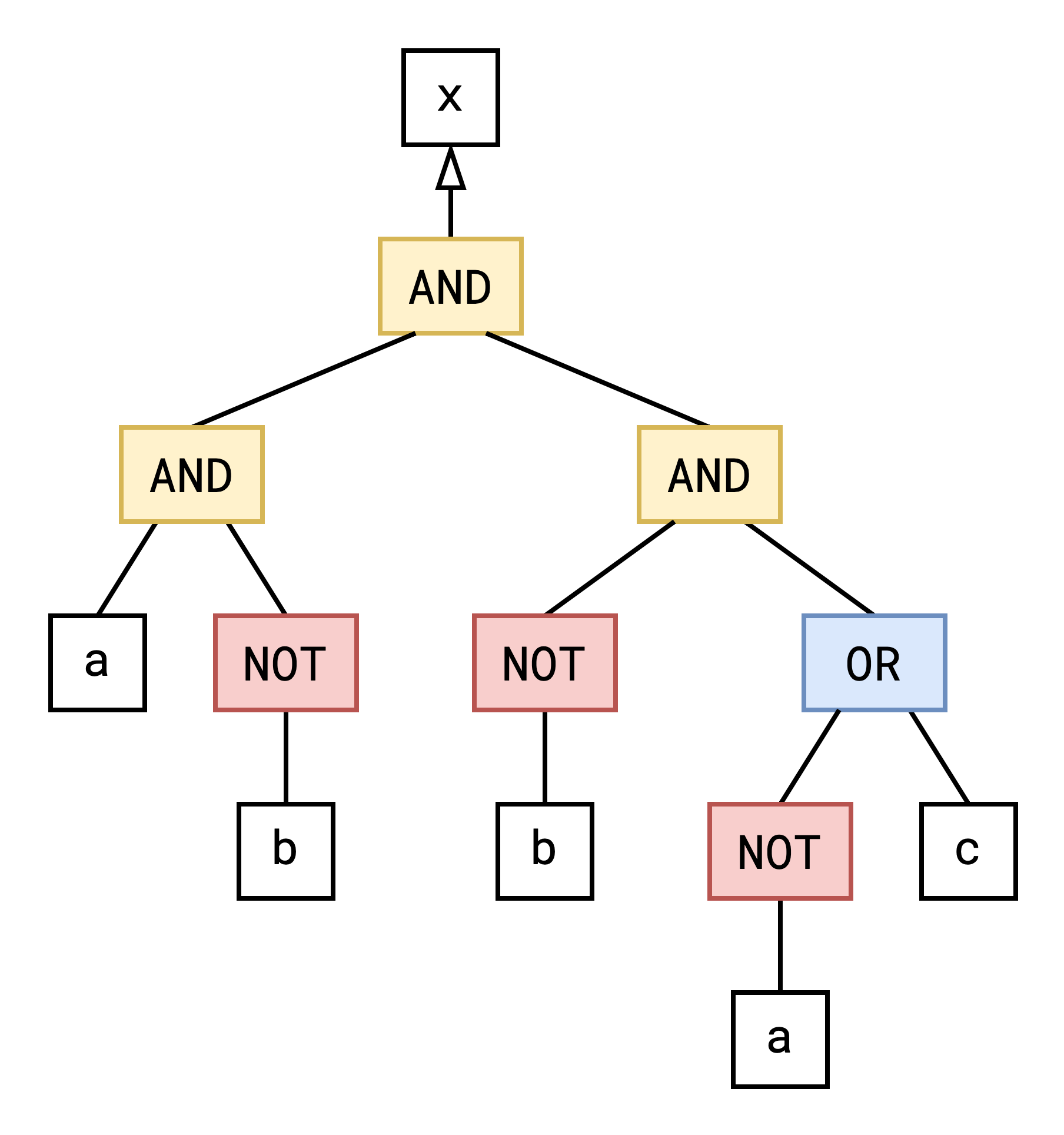
In this AST, nodes represent binary operations (AND, OR and NOT) and the leaf nodes are binary variables. The SAT solver will transform this format into alternate representations which are easier to work with.
Note that this AST is completely equivalent to the text form:
x = (a and (not b)) and ((not b) and ((not a) or c))
it is just easier to work with in a computer (rather than doing a bunch of text parsing over and over…).
3SAT + Reductions
One of the coolest things about complexity theory is that we can transform one type problem into another through reductions.
For example, lets imagine someone designs an algorithm that can efficiently solve 3SAT expressions, which have the special form:
(X1 ∨ X2 ∨ X3) ∧ (X4 ∨ X5 ∨ X6) ∧ ... ∧ (Xn-2 ∨ Xn-1 ∨ Xn)
(for prepositional logic newbies, ∨ means OR and ∧ means AND)
I.e. in this expression, at least one of X1/X2/X3 needs to be true and at least one of X4/X5/X6 needs to be true, etc…
It turns out that we can take our original, unrestricted SAT expression and convert it to an eqivalent 3SAT expression in this format (which we will do in just a moment…). Then using this new solver, we can obtain a solution for our original SAT problem.
Therefore, if you can solve 3SAT efficiently, you can also solve SAT efficiently (and vice-versa). Very surprisingly, it turns out that there is an upper bound on how “hard” a problem can be that you can still verify in polynomial time. We call these maximally hard problems NP-complete. Both SAT and 3SAT (as decision problems) are examples of this class and it turns out there are hundreds of other seemingly unrelated problems that are exactly as hard as each other. See this wikipedia list.
The really amazing thing about NP-complete problems is that any NP problem can be converted into an equivalent NP-complete problem. In other words, any problem which we can verify efficiently can be converted to a 3SAT problem or SAT problem or any of the hundreds of problems in the list above. And since NP-complete problems are in NP by definition, they can all be converted into eachother!
Side note: any problem which is at least as hard as an NP-complete problem is also called NP-hard. All NP-complete problems are also NP-hard by definition. The distinction here is that these problems do not necessarily need to be verifiable in polynomial time (i.e. they may not be NP). Undecideable problems such as the halting problem are examples of this class.
Also hey, remember that note earlier about how verifying a SAT expression might not technically be in polynomial time? Well here, the number of clauses is strictly bounded by the number of variables: C <= (N^3)/6. Duplicated clauses don’t affect the expression and we can trivially remove them. Therefore, we can definitely verify this in polynomial time w.r.t the number of variables.
SAT -> 3SAT
Lets explore an example of a reduction (and one which was used in this CTF problem). We will transform our original SAT abstract sytax tree into an equivalent 3SAT problem.
We start by assigning labels to all of our intermediate nodes:
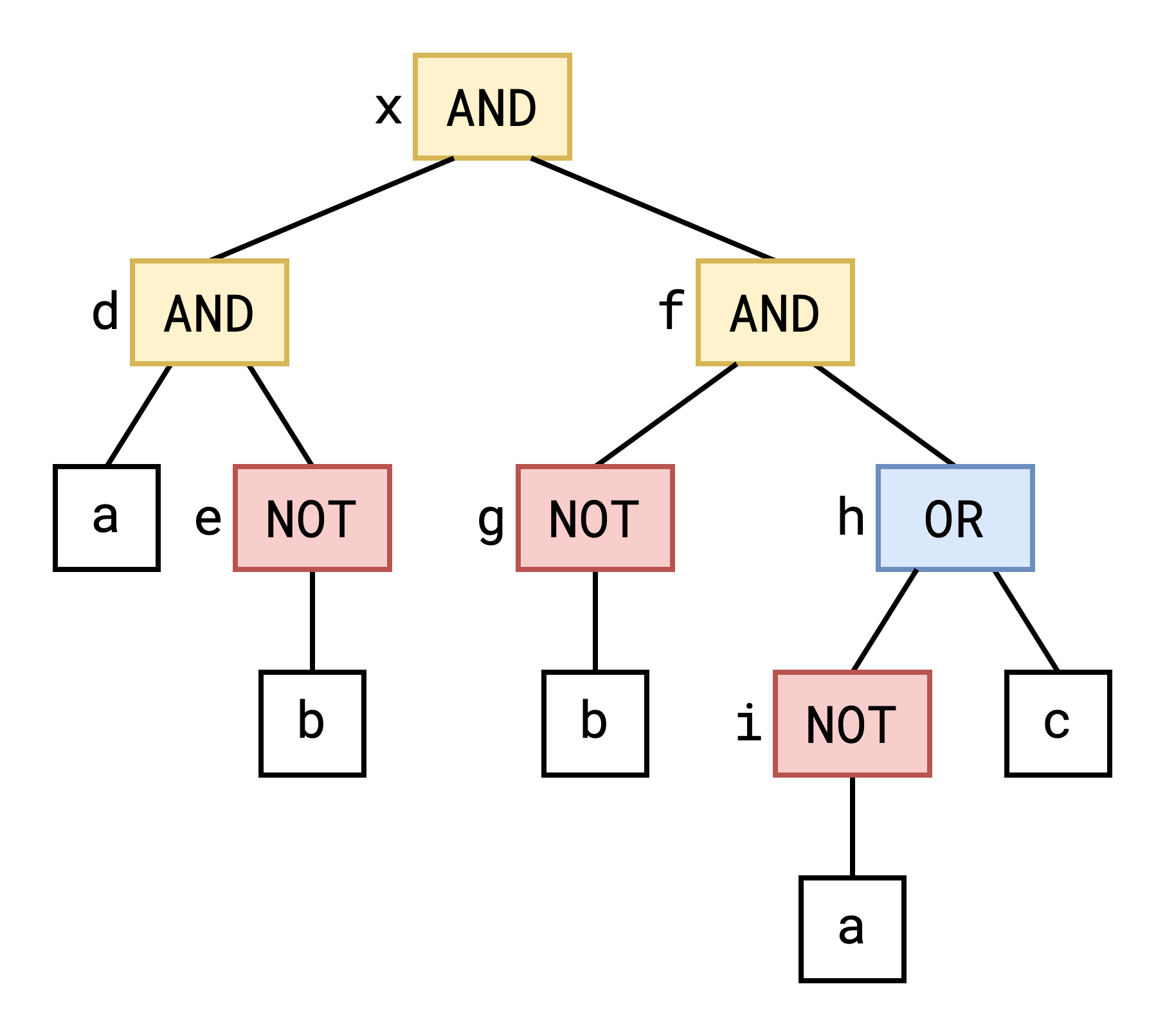
Now we can convert each of our boolean operators into 3-tuples representing clauses in our 3SAT expression. For example, starting with the e = not b clause, we can generate the expression:
(e ∨ e ∨ b) ∧ (¬e ∨ ¬e ∨ ¬b)
If we want want both expressions to evaluate to true (which is necessary for our entire expression to be true), we need either e or b to be true in the left clause.
- If we pick
e, we need¬bfor the right expression. - If we pick
b, we need¬efor the right expression.
Our only two options for satisfiablilty are (e, ¬b) and (¬e, b) and hence we can see that e must be the oposite of whatever b is.
Now lets look at an AND expression. Specifically d = a and e. Note: we no longer care about the leaf node under e (that was the purpose of creating these intermediate labels).
We can create the following expression:
(¬d ∨ e ∨ e) ∧ (¬d ∨ a ∨ ¬e) ∧ (d ∨ ¬a ∨ ¬e)
We can enumerate the possible solutions:
- pick
¬dfor the first clause- pick
afor the second clause(¬d, a, ¬e)
- pick
¬efor the second clause(¬d, a, ¬e)or(¬d, ¬a, ¬e)
- pick
- pick
efor the first clause- pick
¬dfor the second clause(¬d, ¬a, e)
- pick
afor the second clause(d, a, e)
- pick
Notice that the only solution with d is when a AND e are true. Any other combination of a and e forces ¬d and hence d is “tied” to the expression a and e.
To convert our whole AST, we simply go step by step like this and convert each clause.
Here is a cheat sheet of SAT to 3SAT conversions:
a (i.e. a is true):
(a ∨ a ∨ a)
a = not b
(a ∨ a ∨ b) ∧ (¬a ∨ ¬a ∨ ¬b)
a = b and c
(¬a ∨ c ∨ c) ∧ (¬a ∨ b ∨ ¬c) ∧ (a ∨ ¬b ∨ ¬c)
a = b or c
(a ∨ a ∨ ¬c) ∧ (a ∨ ¬b ∨ c) ∧ (¬a ∨ b ∨ c)
a = b xor c
(a ∨ b ∨ ¬c) ∧ (a ∨ ¬b ∨ c) ∧ (¬a ∨ b ∨ c) ∧ (¬a ∨ ¬b ∨ ¬c)
Independent Sets
Imagine a graph consisting of vertices with edges between them. For example, here’s a graph:
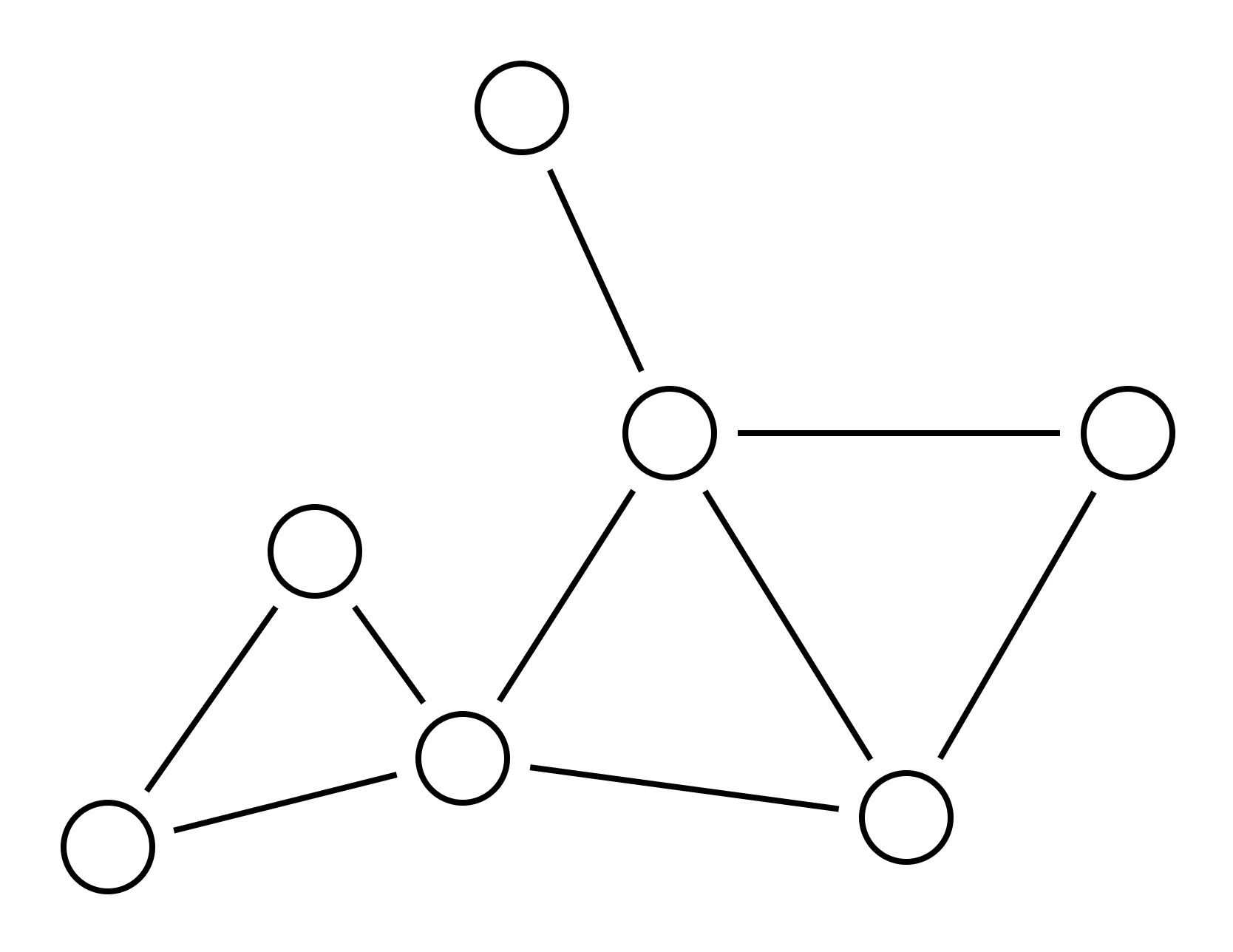
The independent set problem asks: “Can you select N vertices such that none are adjacent?” In this graph, the answer for N<=3 is yes, as shown below. But the answer for N>3 is no.
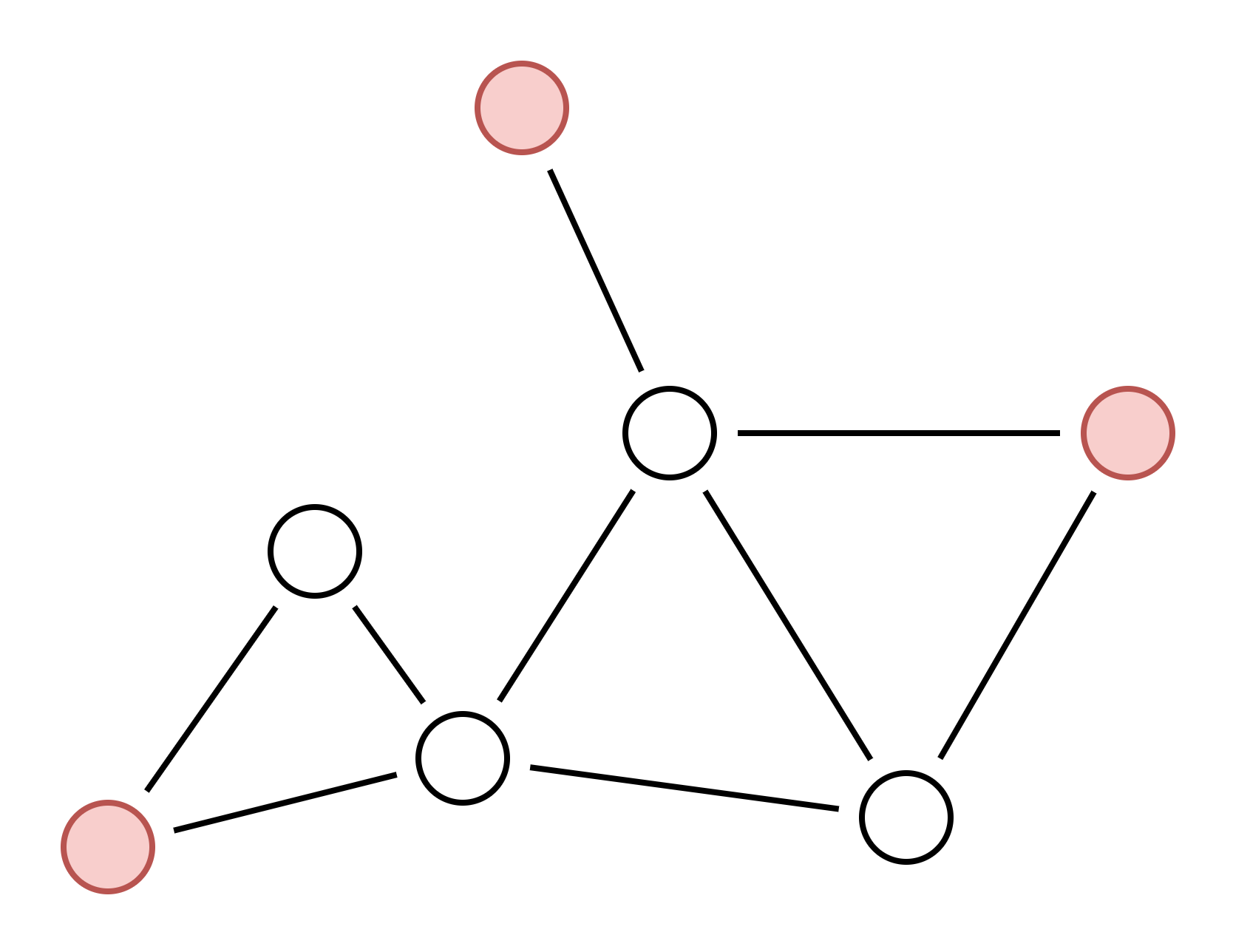
It is proven that the independent set problem is NP-complete which means that it is an example of the hardest NP problems. Remember, this means that any problem in NP can be converted into an equivalent independent set problem.
It is hard to overstate how amazing that fact is. Here we have a pretty boring problem about graphs and vertices. This independent set problem feels arbitrary and yet it is fundamentally the same problem as hundreds of other seemingly unrelated problems.
3SAT -> Independent Set
To demonstrate the claim in the previous section (and because it is relevant for the CTF problem), lets reduce a 3SAT problem into an independent set problem.
Given the expression a = b and c (see the cheat sheet above) we have the following 3SAT expression:
(¬a ∨ c ∨ c) ∧ (¬a ∨ b ∨ ¬c) ∧ (a ∨ ¬b ∨ ¬c)
The first step is to create a vertex for each part of the clause:
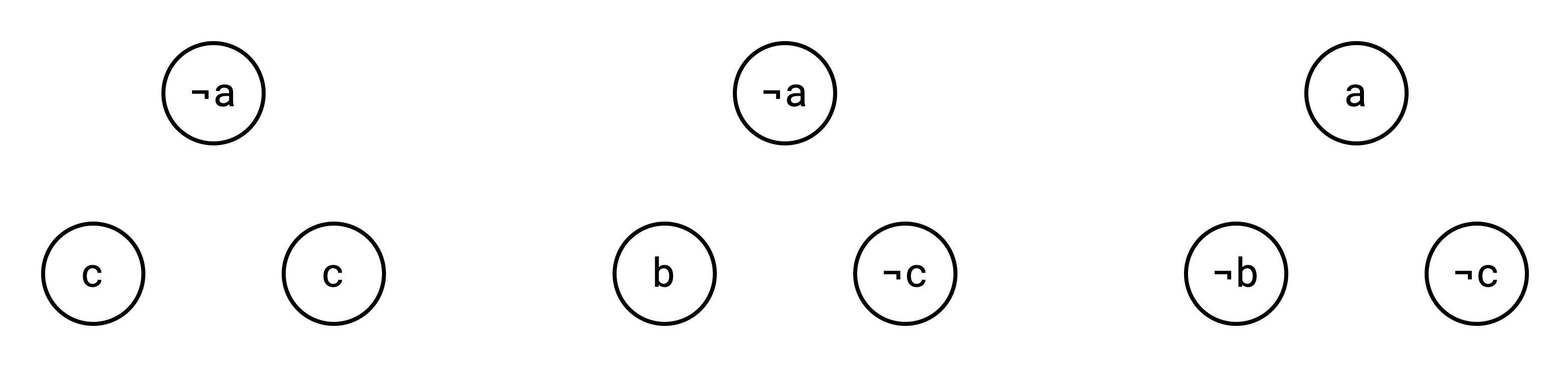
Next, we add edges betwen vertices from the same clause:
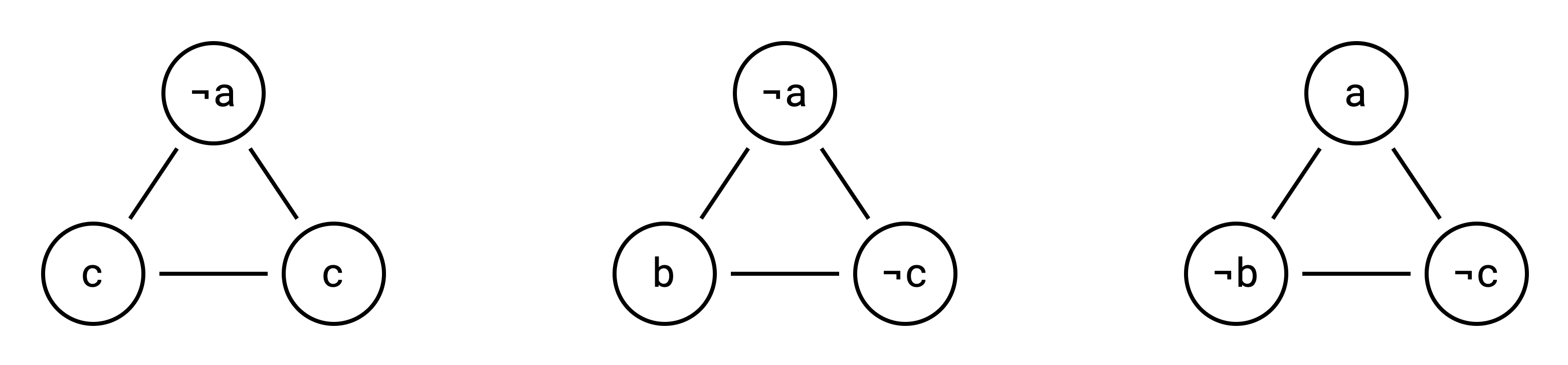
Intuitively, this means that in our solution (if one exists), we can pick a maximum of one vertex from each clause (since vertices from the same clause are now adjacent). Finally, we add edges from any variable to its inverse:
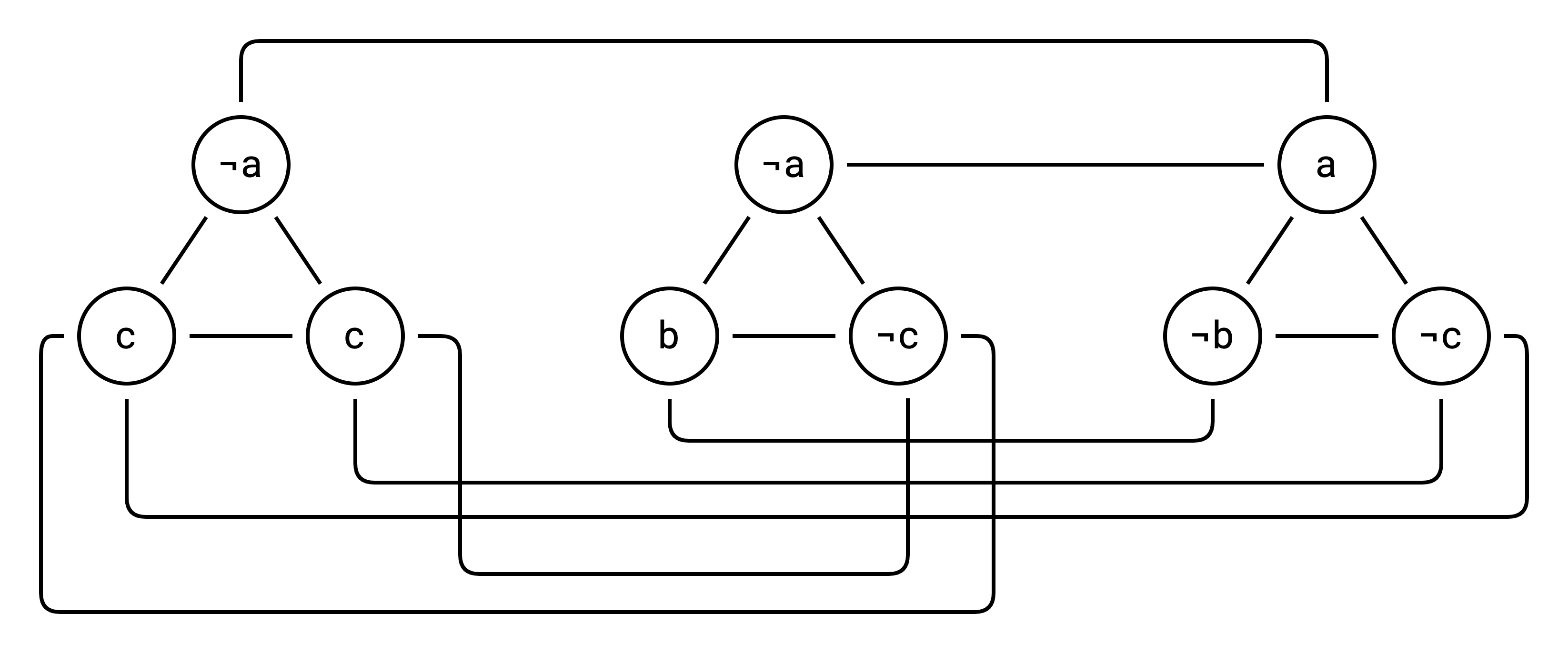
Now we can no longer select a variable and its inverse in the same set. I.e. we need to either select a or ¬a but not both. And the vertex labels are just a visual aid, we don’t actually need them anymore:
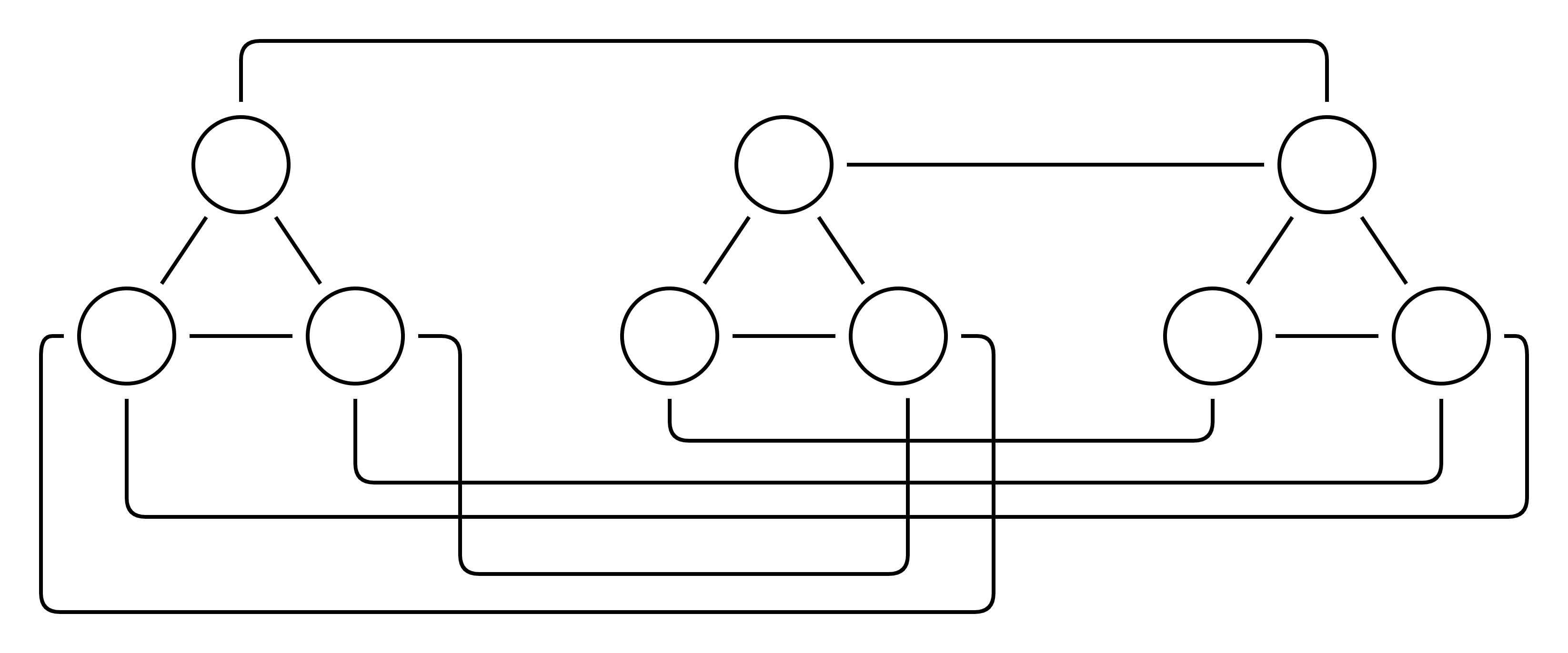
Now we ask the question “Can you select 3 vertices such that none are adjacent?” We pick 3 here because we had 3 clauses in our original 3SAT problem. Any solution to this problem would require picking one vertex from each of the original 3SAT clauses.
In fact there are several solutions to this graph (because a, b and c are all unconstrained). Here is one solution representing the case (¬a, b, ¬c):
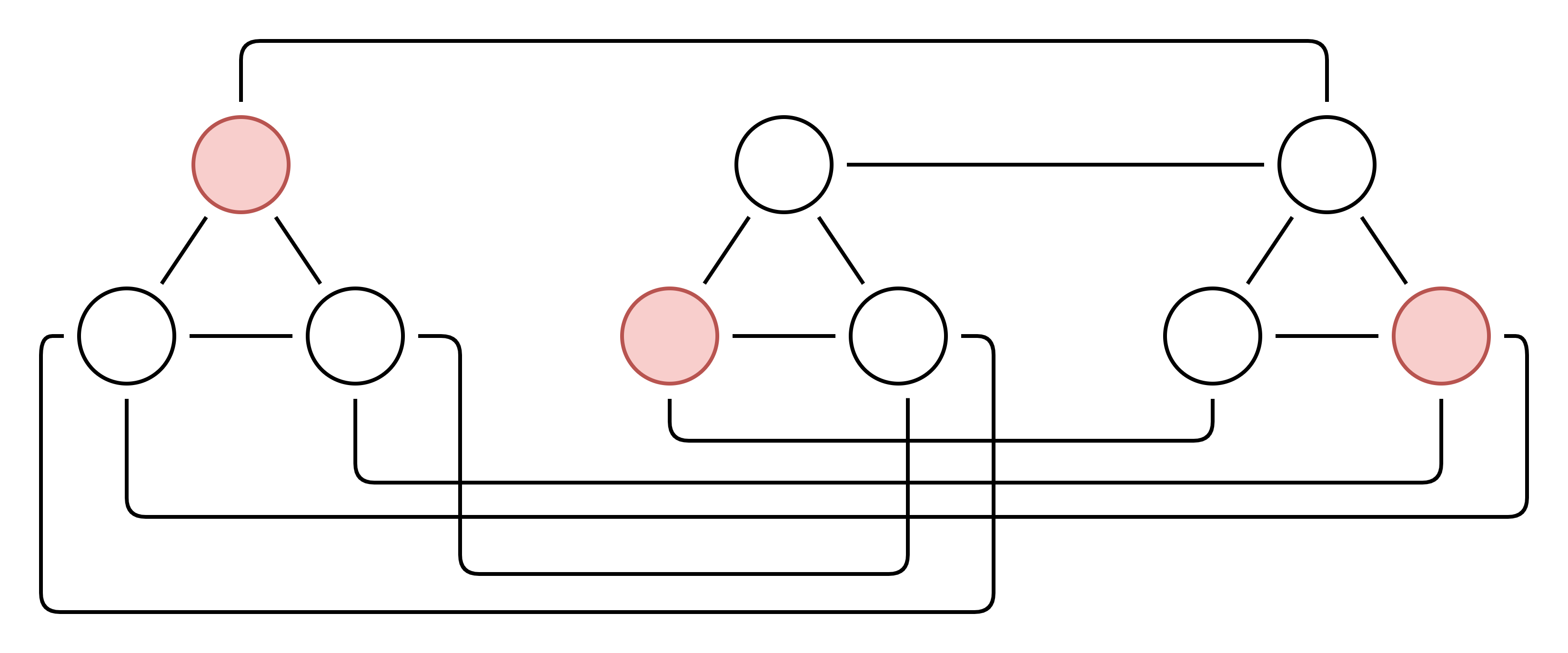
Now let’s add the clause a (i.e. a is true). In our 3SAT expression, this requires adding the clause:
(a ∨ a ∨ a)
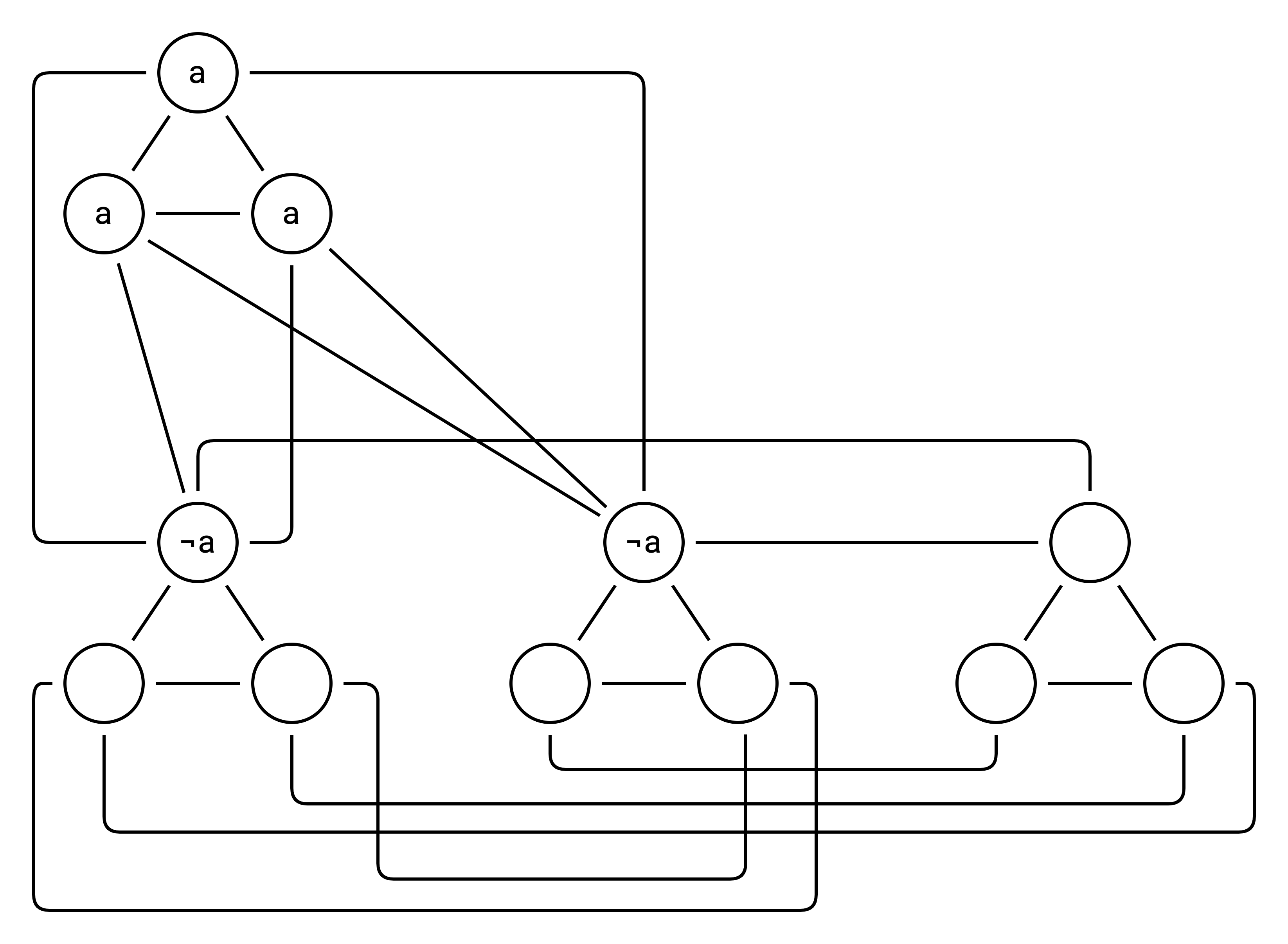
Now we ask: “Can you select 4 vertices such that none are adjacent?”
The answer is yes and there is now just one solution representing the case where b and c are true:
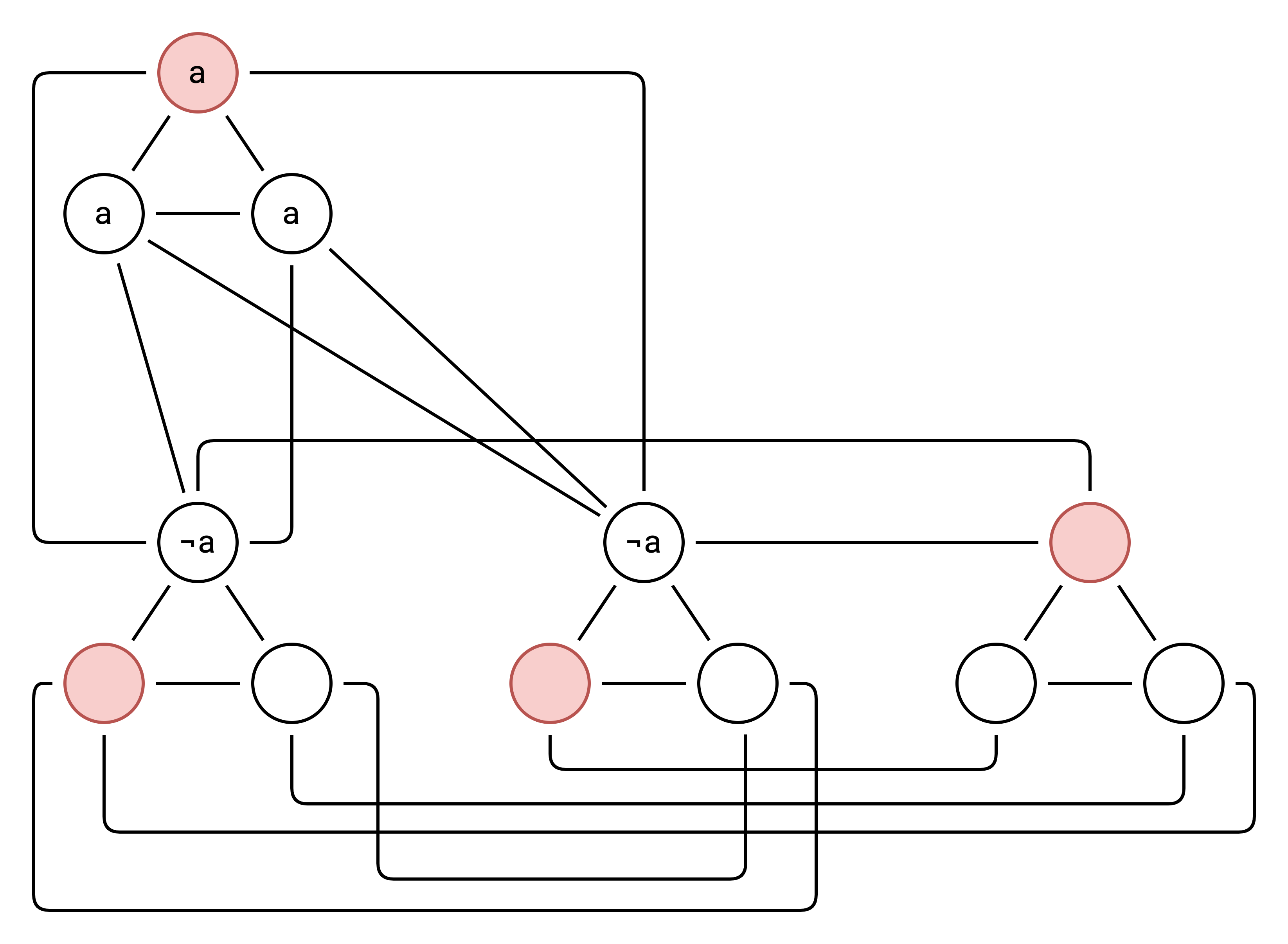
Now let’s try adding the clause b = not c, as 3SAT:
(b ∨ b ∨ c) ∧ (¬b ∨ ¬b ∨ ¬c)
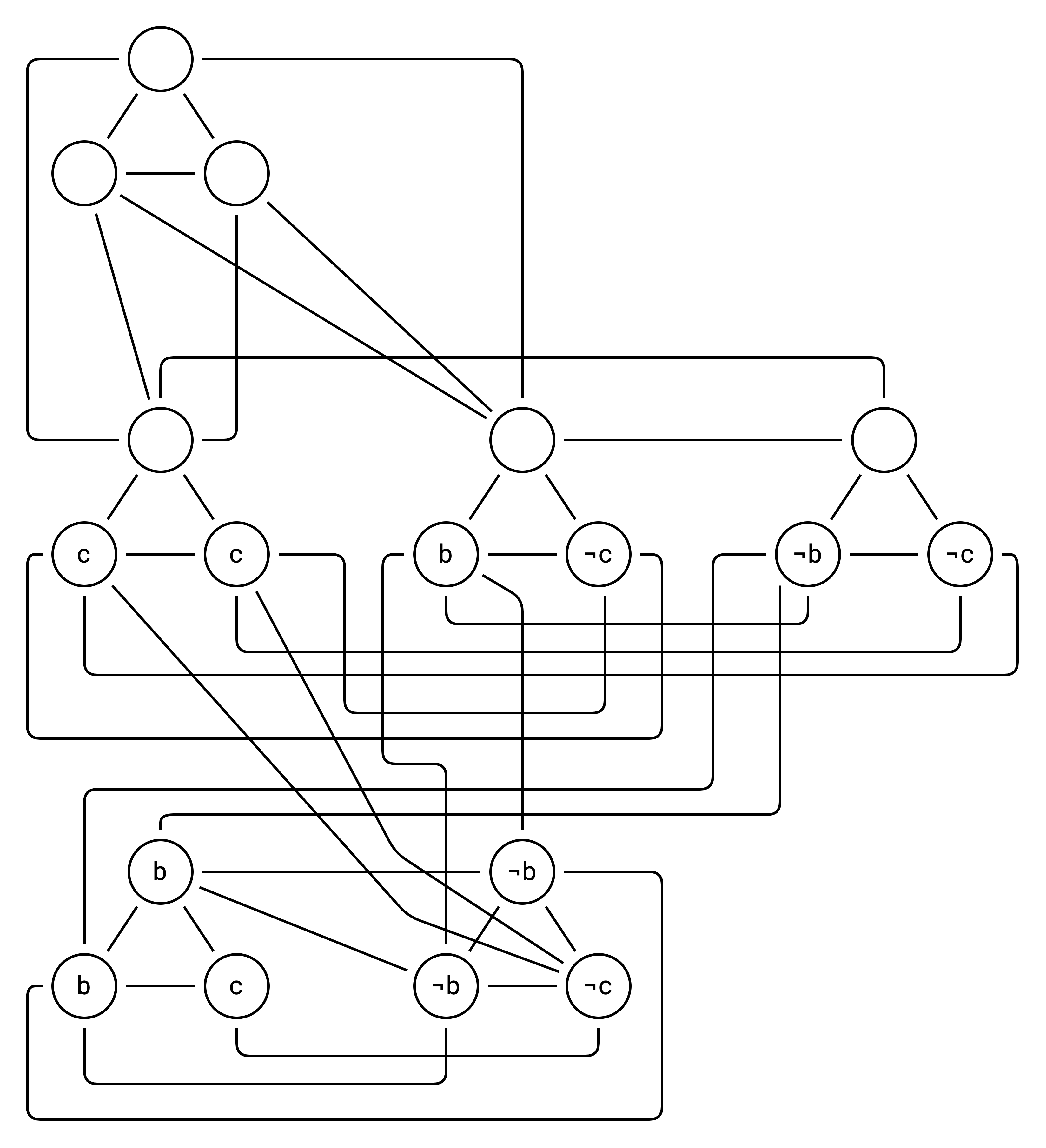
We ask: “Can you select 6 vertices such that none are adjacent?”
The answer now is no because this original SAT expression (c and (not c)) is unsatisfiable. You can try if you want, but it is not possible to find a set of 6 vertices in the above graph such that none are adjacent.
The CTF Problem
Now that we have covered some prerequisite knowledge, lets dive into the actual CTF problem. At first glance, we can see that there are symbols (woohoo!) but it is also a C++ binary (boo!).
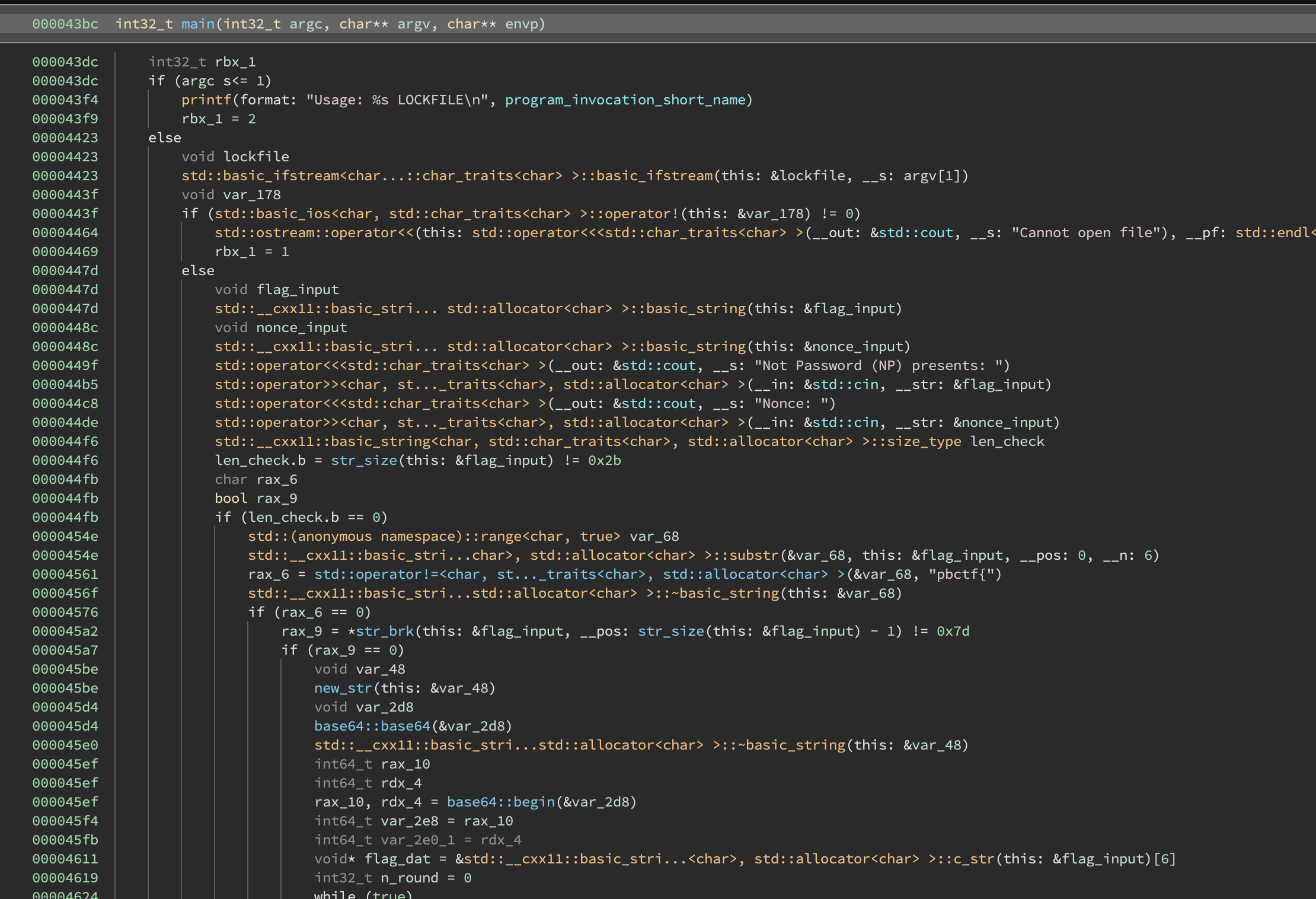
The main function asks for a flag input and a nonce. It checks if our flag has the format pbctf{<36 chars>}. Then it calls the round function repeatedly on consecutive 4-byte chunks of the inner part of the flag.
There are two additional arguments to round: a base64 object related to the nonce (which I actually ignored during reversing) and an object obtained by deserializing a chunk of the lockfile.
Round
Upon looking at the round function we see some interesting function calls:
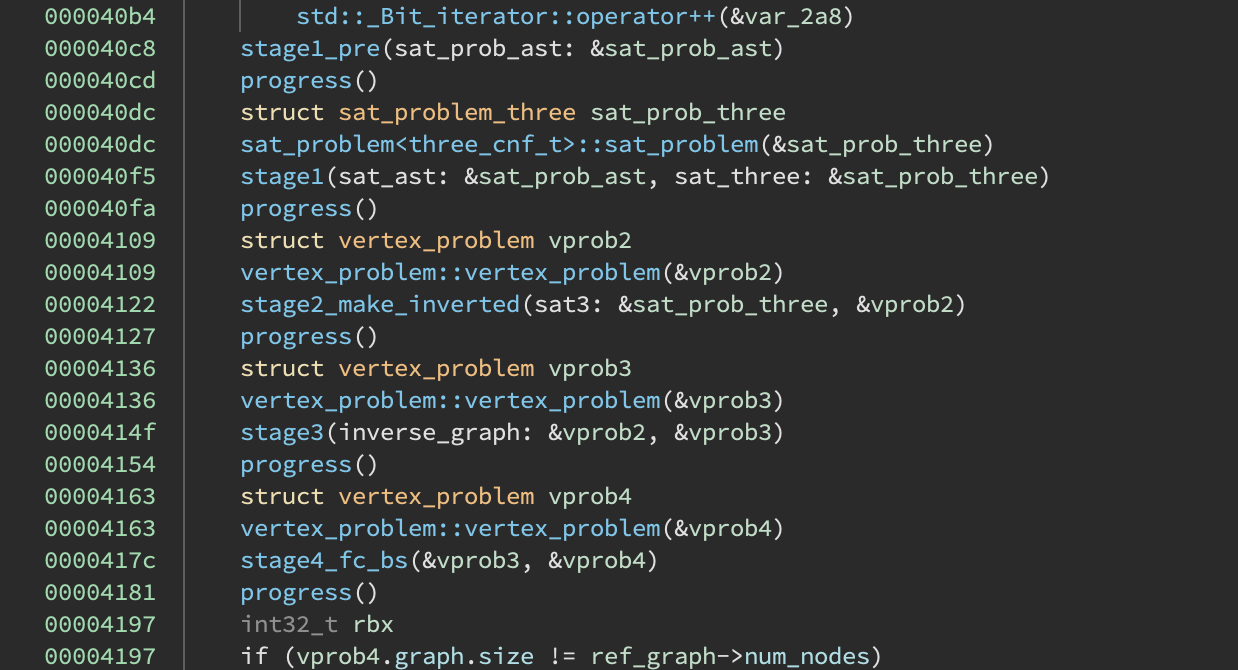
At this point, I started to get a sense of the general challenge. These functions seem to indicate that it is doing some sort of reduction from SAT to 3SAT to independent set. For most of the reversing process, I actually thought this vertex step was the vertex covering problem which is related to the independent set problem and has a similar reduction strategy.
At the start of round we see the following type of construction:
typedef shared_ptr<ast_t> ast;
bool round(uint32_t flag_chunk, ...) {
ast_prgm program;
int a = program.resv_num<uint32_t>();
int b = program.decl_num<uint32_t>(flag_chunk);
int res = program.add_num(
size=0x20, op1=a, subtract=true, op2=b);
ast bts = var(program.any_bits(size=0x20, res));
// invokes custom operator
ast inv_bts = !bts;
program.seq(inv_bts);
...
}
Here ast_prgm represents an AST SAT problem like we described earlier. The constructor initializes the following tree:
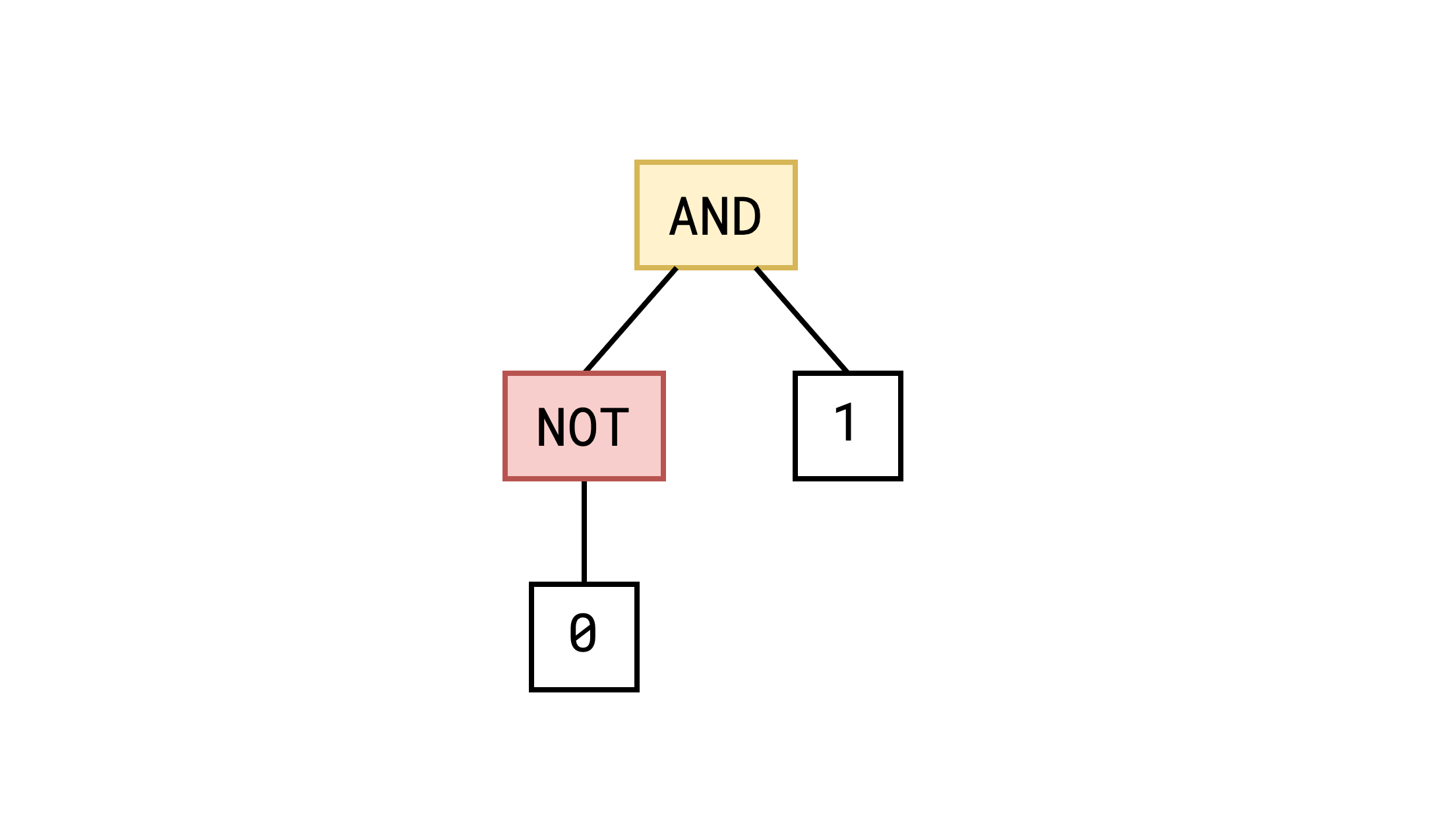
ast_prgm::resv_num<T> simply allocates N boolean variables where N is the bitsize of T. In this case, it allocates 32 boolean variables and returns the number of the first one.
decl_num reserves and then sets those bits equal to a fixed value:
using namespace std;
typedef shared_ptr<ast_t> ast;
struct ast_prgm {
int decl_num<uint32_t>(uint32_t val) {
int ref = this->resv_num<uint32_t>();
for (int i = 0; i < 0x20; ++i) {
ast x = var(ref++);
if ((val >> i) & 1) {
this->seq(!x);
} else {
this->seq(x);
}
}
}
}
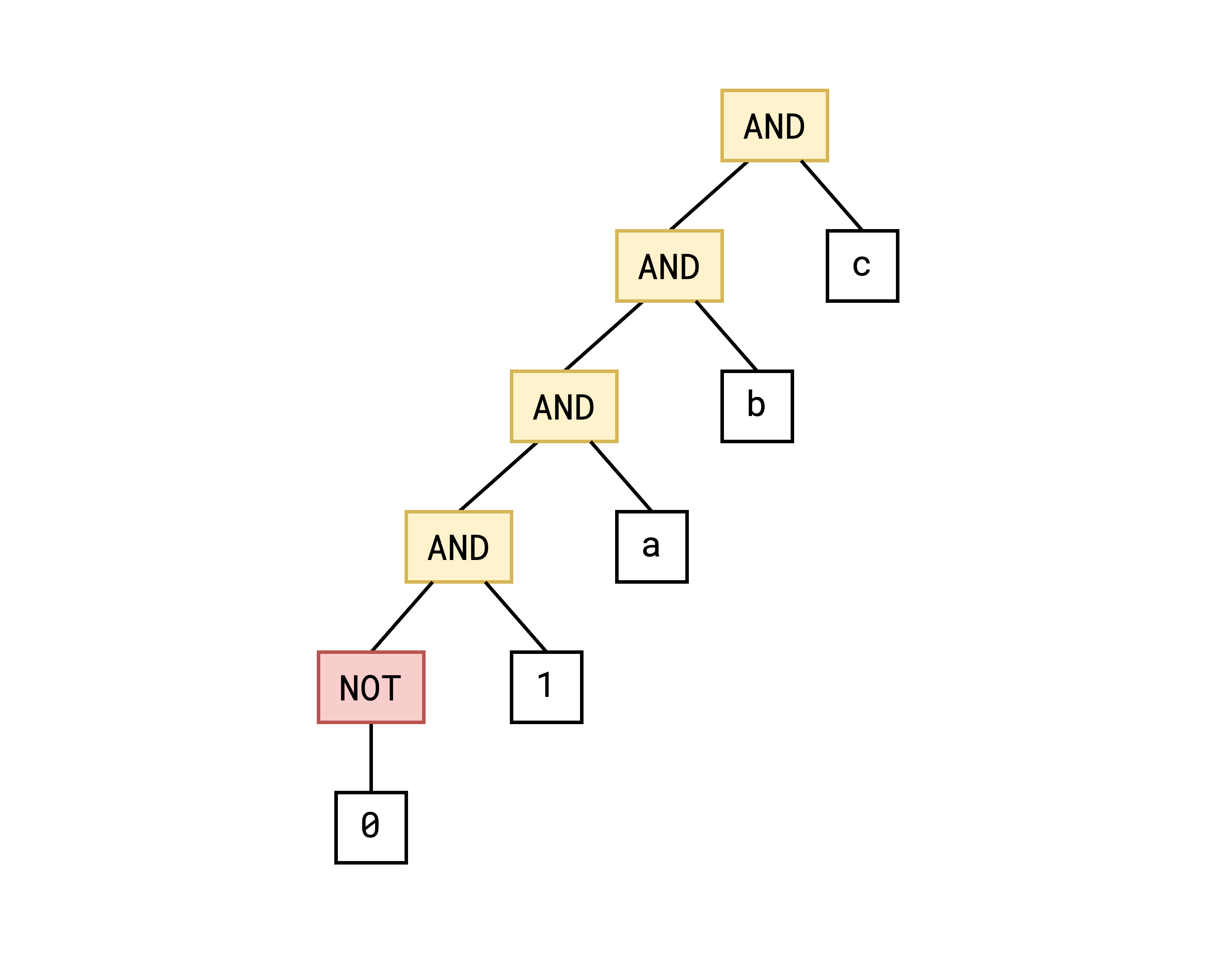
ast_prgm::seq(var) is the equivalent of z3.Solver.add(x), it simply appends an AST subtree to the main tree. For example, invoking
program.seq(a);
program.seq(b);
program.seq(c);
produces the following tree:
ast_prgm::add_num performs either binary addition or subtraction depending on the sub flag:
using namespace std;
typedef shared_ptr<ast_t> ast;
struct ast_prgm {
int add_num(int size, int op1, bool sub, int op2) {
int res = this->resv(size);
// var(0) and var(1) are fixed to 0 and 1
ast c = sub ? var(1) : var(0);
for (int i = 0; i < 0x20; ++i) {
ast a = var(op1+i);
ast b = sub ? !var(op2+i) : var(op2+i);
ast s = ((a ^ b) ^ c);
ast co = ((b & c) | (a & c)) | (a & b);
// i.e. res[i] == s
this->seq((!s) ^ var(res+i));
c = this->resv(1);
this->seq((!co) ^ c);
}
return res;
}
}
Finally, ast_prgm::any_bits simply computes a boolean value that is True if any of the input bits are set:
using namespace std;
typedef shared_ptr<ast_t> ast;
struct ast_prgm {
int any_bits(int size, int op1) {
int res = this->resv(1);
if (size > 0) {
ast r = var(op1);
for (int i = 1; i < 0x20; ++i) {
ast k = var(op1+i);
r |= k;
}
// i.e. res == r
this->seq((!r) ^ var(res));
}
return res;
}
}
So as a whole, this SAT expression is simply creating two 32-bit numbers, one of which is 4 bytes of our flag. Then it performs subtraction and ensures that the resulting number has no bits set.
Obviously this is underconstrained, since whatever flag we give it, there will be a solution. So what is going on?
Graph Comparison
The key is with the end of round:
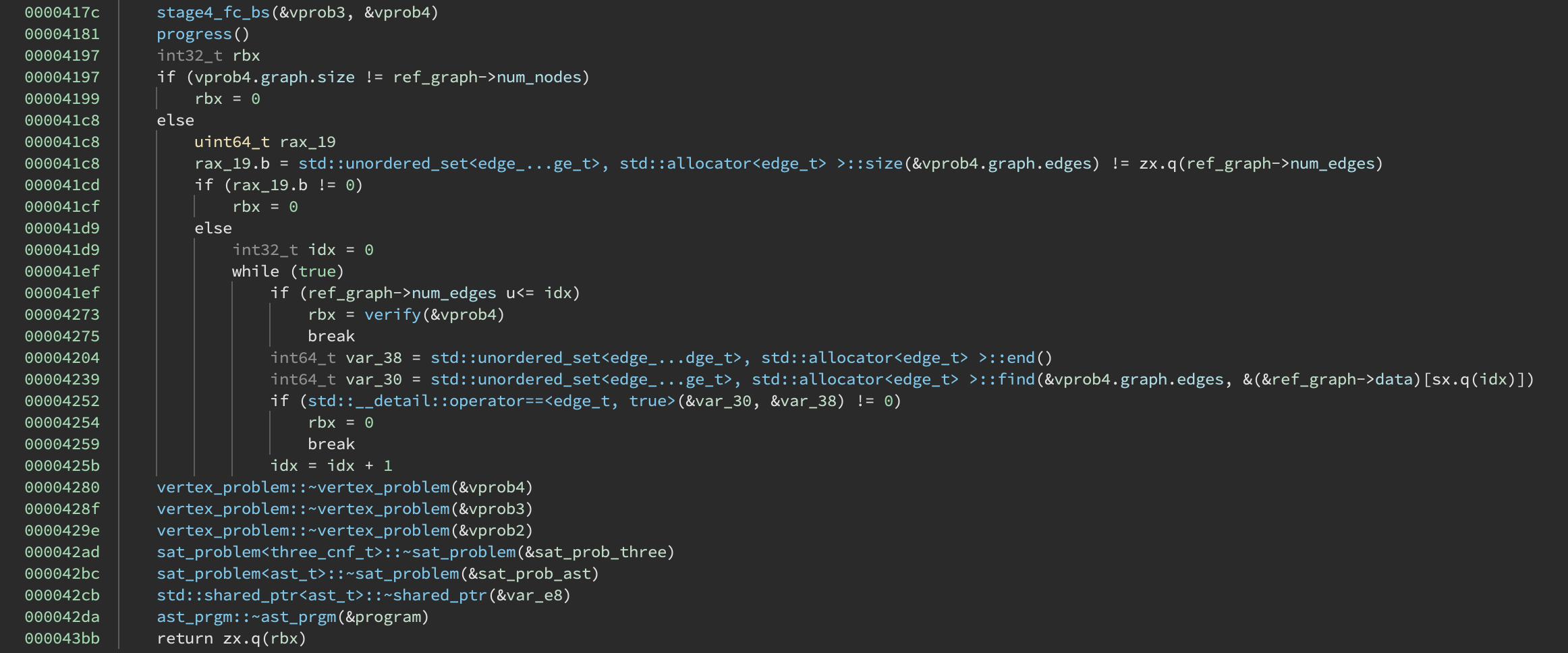
After creating this AST, it computes an equivalent 3SAT problem and then converts that into an instance of an independent set problem. Finally, it compares the graph edges to those obtained by deserializing the lockfile. Ah! So it isn’t actually using the SAT part to validate our flag, it is simply checking if our flag input produces the same independent set problem. And now the description makes a lot more sense!
Not Password is a program where you, well… type not a password and totally does not check your password for correctness.
On disk, the serialized graph format is simply:
[4 bytes] number of nodes
[4 bytes] number of edges
[4 bytes] A1
[4 bytes] A2
[4 bytes] B1
[4 bytes] B2
...
where (A1,A2), (B1,B2) etc… are edges in the graph.
Note: the final graph is actually slightly modified from the original independent set problem but we can still retrieve it. The program actually generates a fully connected graph from vertices 0 to N and then appends pairs of edges of the form (A1,G1),(A2,G1),(B1,G2),(B2,G2) given original edges (A1,A2), (B1,B2) etc…
It may be the case that the author is actually converting to a related graph-based NP-complete problem that I’m not aware of. In any case, it was releatively easy to convert back into an independent set problem which I was able to handle easier.
Reversing Reductions
Now at this point, we’ve obtained a graph that represents an instance of the independent set problem. This problem has a solution if our original SAT problem has a solution. However, since the original problem was underconstrained, this will always have a solution regardless of our flag input. Therefore, trying to find a solution here doesn’t actually help.
Additionally, remember that we no longer have any labels for nodes or variables. The graph itself is completely faceless, just bare vertices and edges.
Luckly, when we invoke ast_prgm::decl_num it embeds our flag into the SAT graph and we can theoretically use this information to recover the flag. Specifically if the first four bits of our flag are 0110, the start of the SAT AST will look like this:
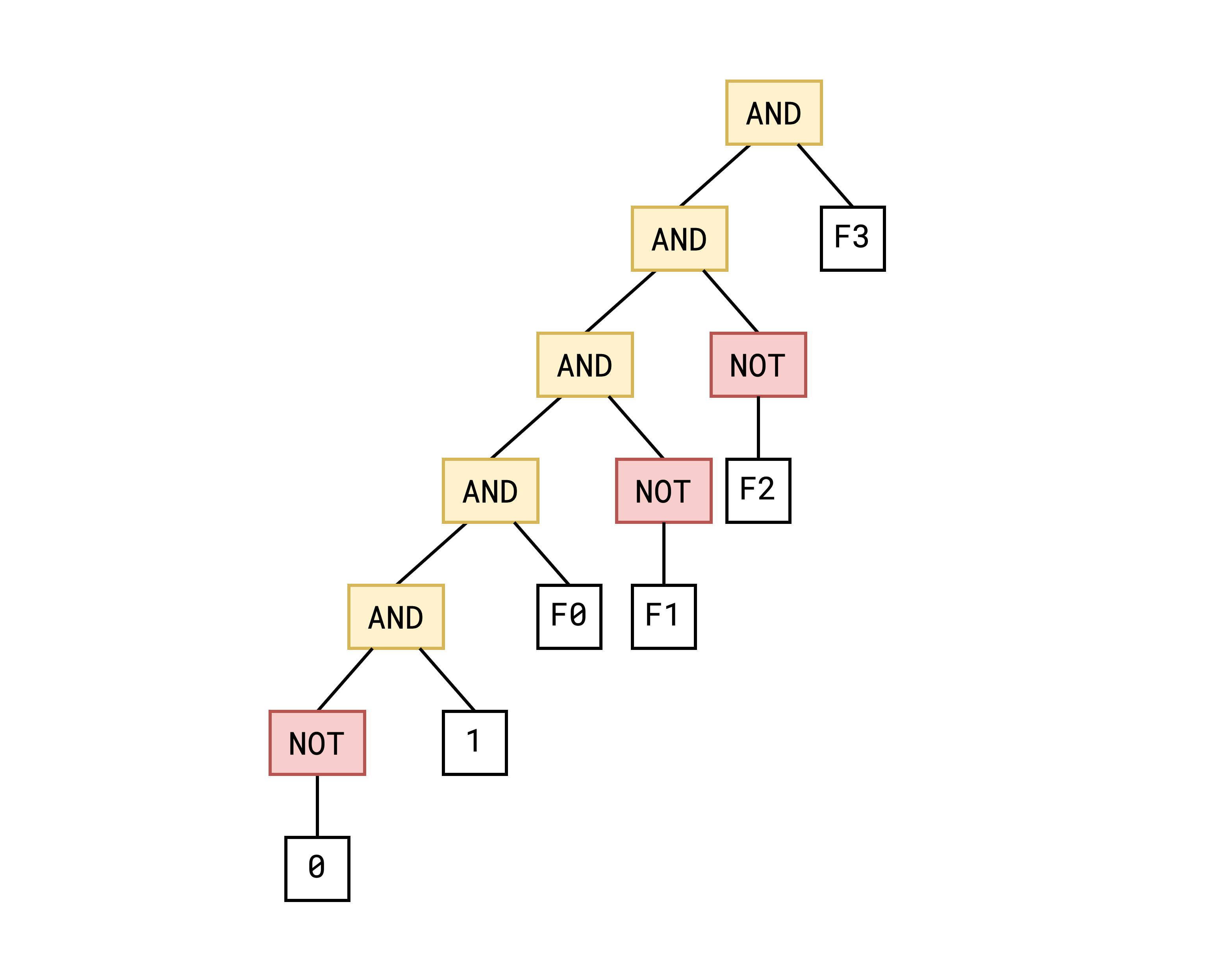
Any 0 bit in the flag will have an extra NOT gate in the SAT graph.
In the general sense, this problem is still really hard: we have a fairly large graph and we have to do some really complicated pattern matching to pull out structures. However, due to a nice quirk of the way the vertex graph was generated we know some additional information that will be useful:
In a single 3SAT clause, vertices are numbered one after the other. For example, the clause
(x ∨ y ∨ z)
would convert into vertices with indexes (N, N+1, N+2) where N is a multiple of three. Additionally, in cases where the SAT AST node generated more than one 3SAT clause, these will be sequential. I.e. given the generated clauses:
(x ∨ y ∨ z) ∧ (a ∨ b ∨ c)
we will obtain indexes (N, N+1, N+2) and (N+3, N+4, N+5) where N is a multiple of three.
Therefore, the strategy I used to identify SAT nodes in generate graph is to iterate over every three indexes and check if the pattern of internal connections for a set of 6, 9 or 12 nodes matches either NOT, OR, XOR or AND.
Specifically, these are the internal connection patterns for each gate:
gates = [
('and', 9, [
(0, 1), (0, 2), (0, 6),
(1, 2), (1, 5), (1, 8),
(2, 5), (2, 8), (3, 4),
(3, 5), (3, 6), (4, 5),
(4, 7), (6, 7), (6, 8),
(7, 8),
]),
('not', 6, [
(0,1), (1,2), (0,2),
(3,4), (4,5), (3,5),
(0,3), (1,3), (0,4),
(1,4), (2,5)
]),
('xor', 12, [
(0,1), (1,2), (0,2),
(3,4), (4,5), (3,5),
(6,7), (7,8), (6,8),
(9,10), (10,11), (9,11),
(0,6), (0,9), (3,6), (3,9),
(1,4), (1,10), (4,7), (7,10),
(2,5), (2,8), (5,11), (8,11)
]),
('or', 9, [
(0,1), (1,2), (0,2),
(3,4), (4,5), (3,5),
(6,7), (7,8), (6,8),
(0,6), (1,6), (3,6),
(4,7),
(2,5), (2,8)
])
]
Each tuple here represents an internal edge. I.e. (1,2) represents the connection from N+1 to N+2. Notice how every gate includes the edges (0,1), (1,2) and (0,2) representing the first “clause triangle” for example.
Using this search strategy, I mapped out which nodes represented each gate, i.e. for one graph we obtain:
{
3: 'and',
12: 'and',
21: 'not',
27: 'and',
36: 'xor',
48: 'and',
57: 'xor',
69: 'not',
75: 'and',
84: 'xor',
96: 'not',
102: 'or',
111: 'and',
120: 'xor',
132: 'not',
138: 'xor',
150: 'or',
159: 'and',
...
}
Additionally, since these nodes are connected, we expect to see edges between them, representing connections in the original AST. For example an edge between vertex 5 and vertex 21 can be decoded in the following way:
- vertex
5isand@3 + 2which is thecsymbol from 3SAT form, for reference:
(¬a ∨ c ∨ c) ∧ (¬a ∨ b ∨ ¬c) ∧ (a ∨ ¬b ∨ ¬c)
^
here
- vertex
21isnot@21 + 0which is theasymbol from 3SAT form:
(a ∨ a ∨ b) ∧ (¬a ∨ ¬a ∨ ¬b)
^
here
Therefore, this NOT must be a child of the AND node (specifically a right child since it is connected to c and not b).
One annoying part is that nodes which reference pure symbolic variables (and not other nodes) don’t actually have connections in the graph. However, if two nodes share the same symbolic child, they will be connected together. So you can use this information to work out where references must exists and I simply added some blank ref nodes to my generated graph in these cases.
Decoding the entire graph in this manner allows us to extract the original AST structure, which I think looks amazing:
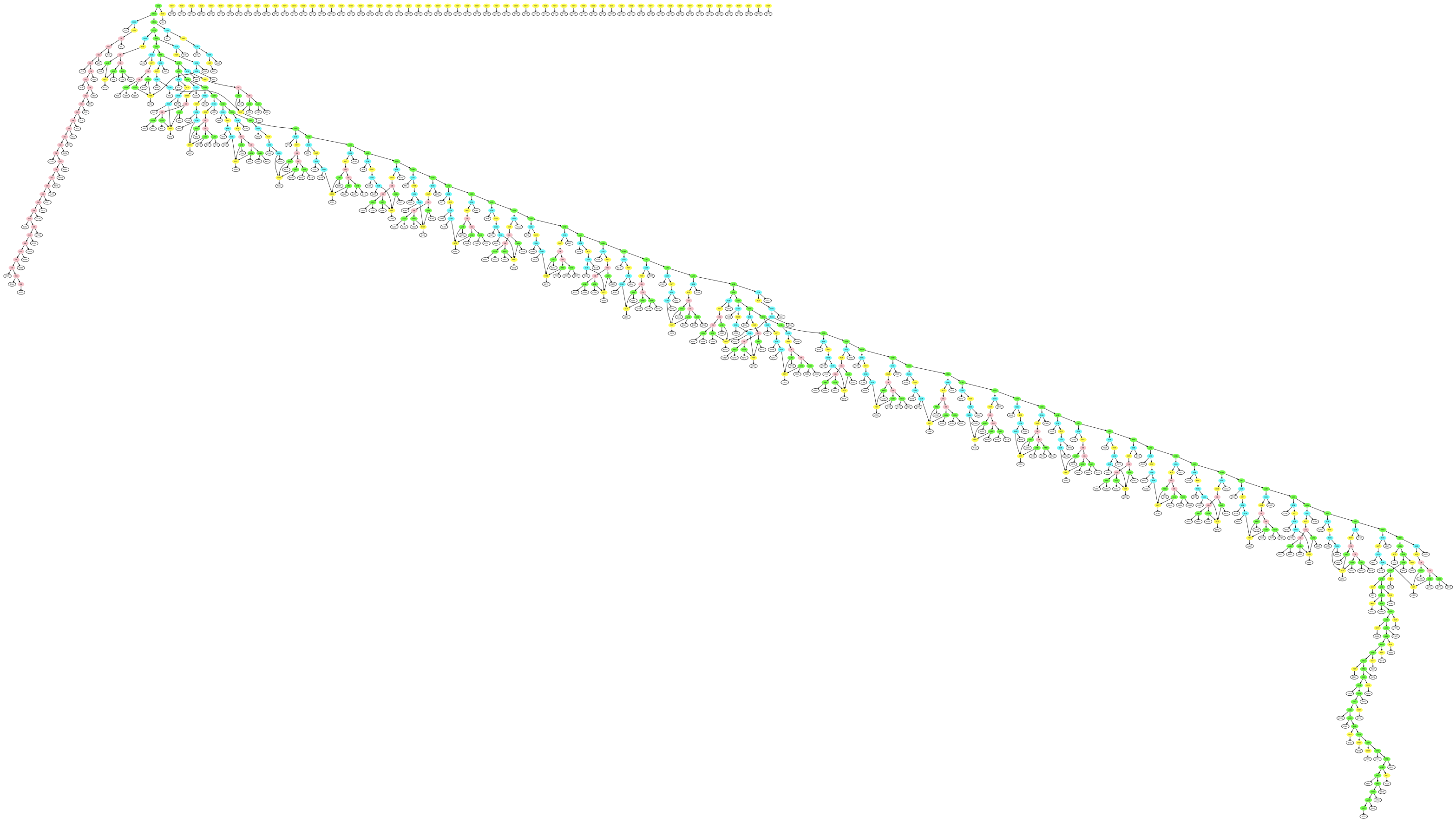
Green=AND, Blue=XOR, Yellow=NOT, Pink=OR, White=var
If you’re interested, I’ve uploaded a full-resolution pdf of this graph here: graph.pdf
Zooming in on some structures we can see the adder circuit:
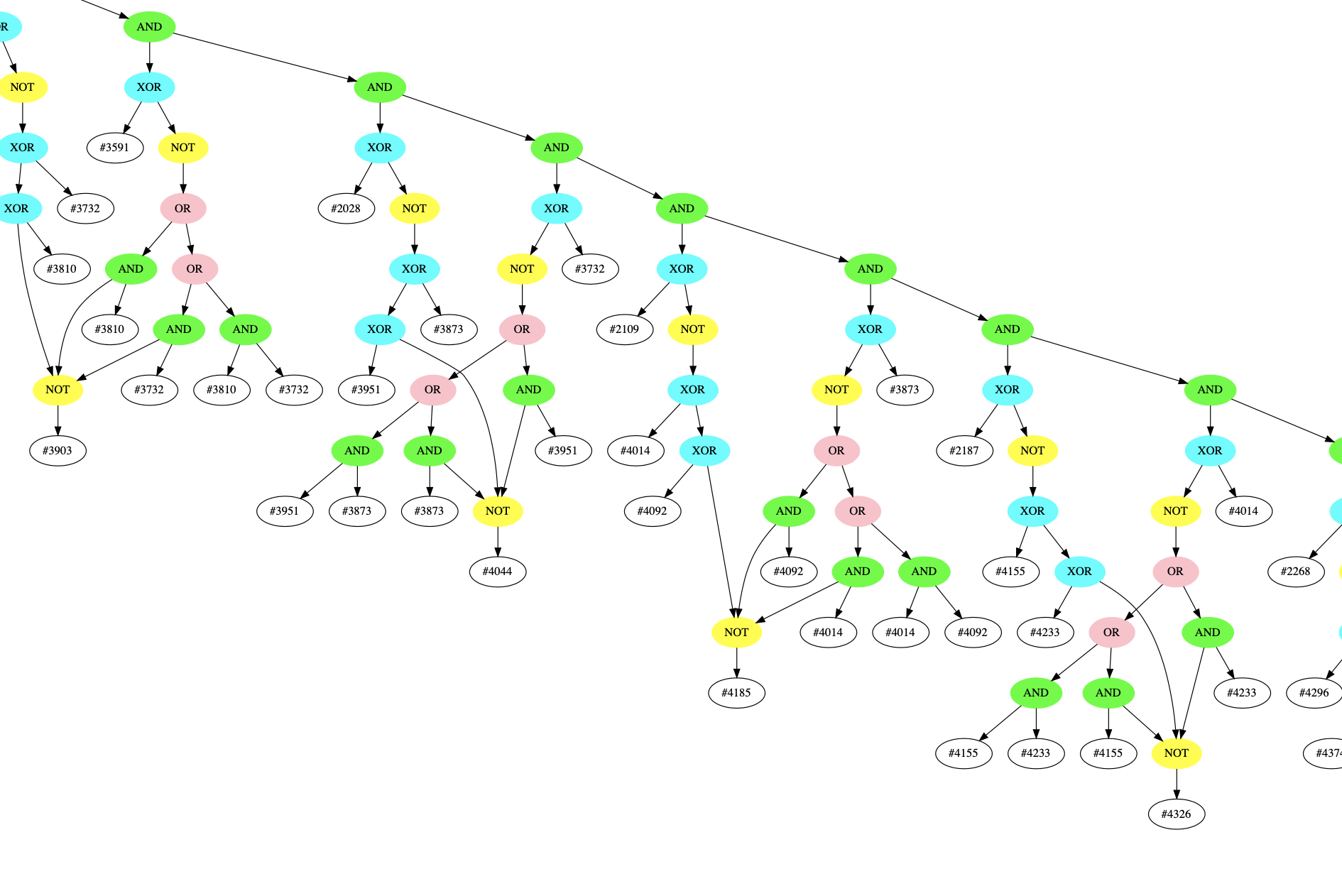
And we can see the any_bits OR-chain near the end:
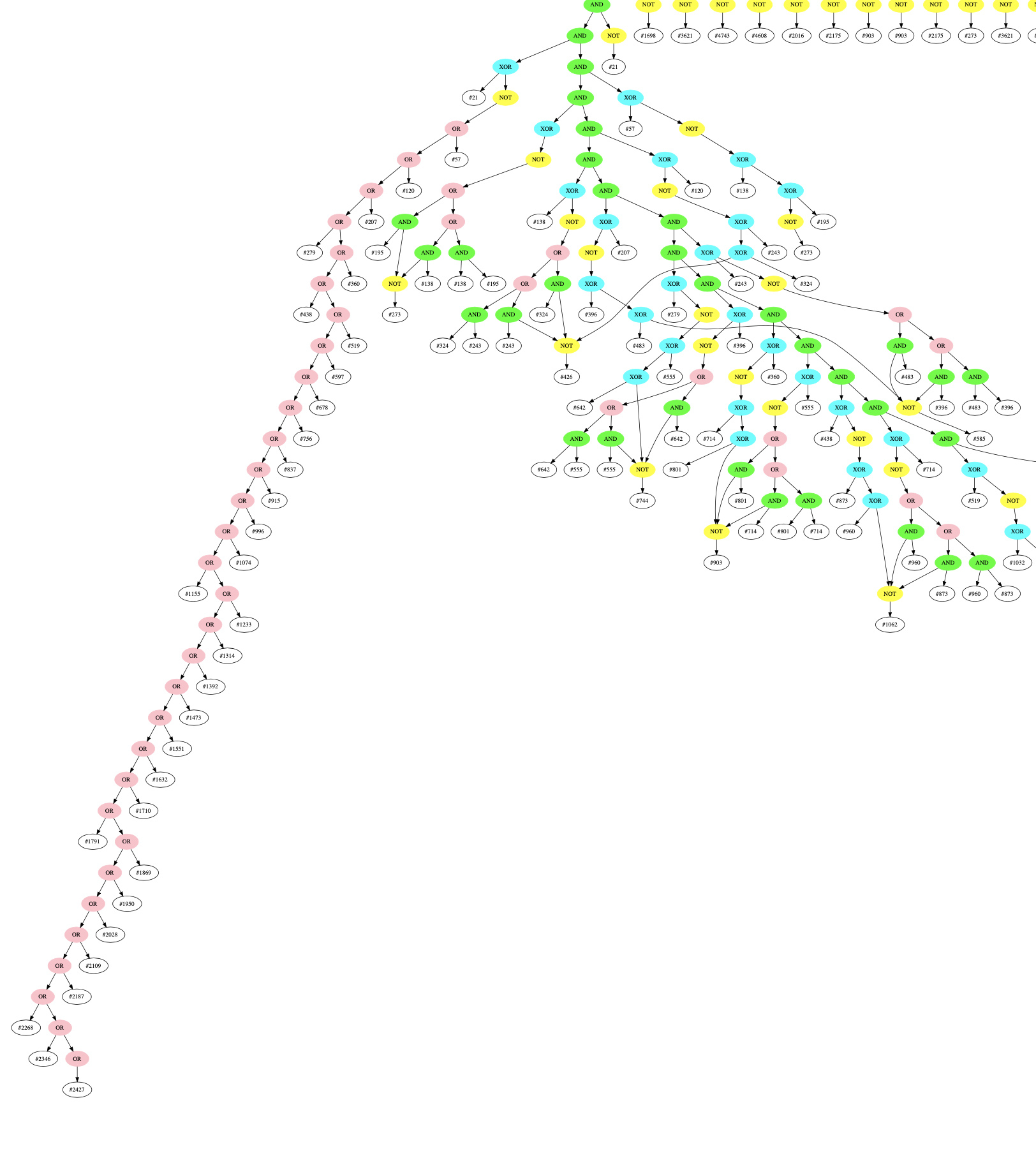
And importantly, we can see our flag encoding!
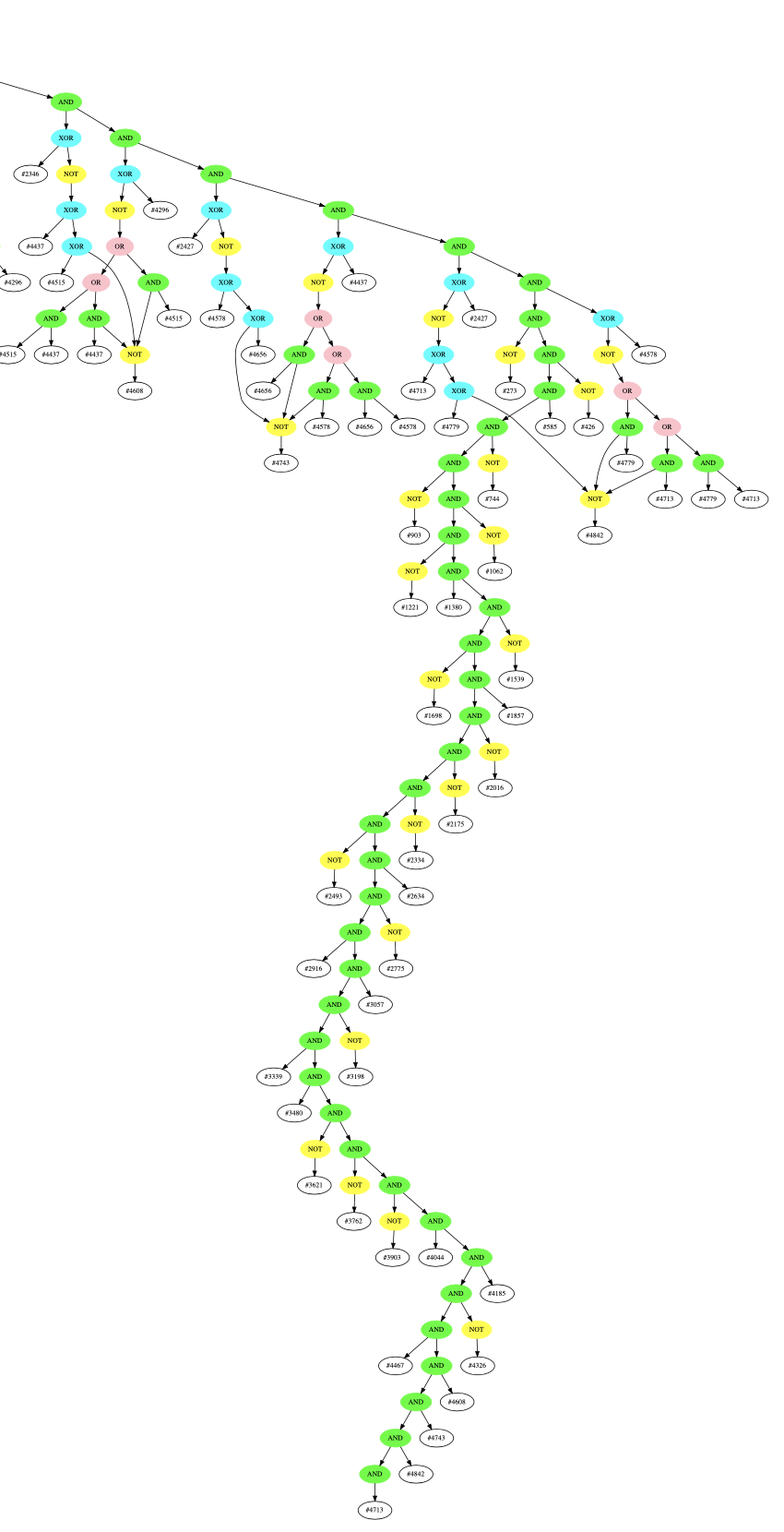
Decoding
Unfortunately, the original lockfile was slightly corrupted so some flag bits ended up decoding wrong. But I posted some near-flag solutions in the discord and my teammates were able to help guess-god what ASCII solution made sense.
pbctf{W0w_NP-C0mpl3t3n3ss_1s_pr33ty_c0ol!!}
I totally agree, NP-Completeness is cool!
Final Thoughts
I really enjoyed this challenge! During the solving process I had to re-learn a lot about complexity theory that I had forgotten from classes and I learned a lot of new stuff along the way.
I think this problem would have been a lot harder if the vertex indexes were shuffled, something to think about for future ctfs…
Also, this could be a really cool way to obfuscate code. Since the generated graph has no label information it’s almost the equivalent of stripping symbols from a binary but at an even deeper computational level.
P.S. Please let me know if I got anything wrong about complexity theory, I did a lot of googling for this writeup and I might have interpreted some things wrong ;p You can DM me on Twitter: @hgarrereyn or Discord: (hgarrereyn#1414) or use the Disqus comment section below.